- A parte de Econometria no R é baseada no livro de Florian Heiss “Using R for Introductory Econometrics” (2ª edição, 2020)
- Aplica no R o conteúdo e os exemplos do livro do Wooldridge de 2019 (versão em inglês)
- É possível ler gratuitamente a versão online em: http://www.urfie.net
- Há também uma versão de Python do livro em: http://www.upfie.net
- A base de dados dos exemplos contidos no livro do Wooldridge podem ser obtidos por meio da instalação e do carregamento do pacote
wooldridge:
install.packages("wooldridge")
Distribuições
-
Probability Distributions in R (Examples): PDF, CDF & Quantile Function (Statistics Globe)
-
As funções relacionadas a distribuições são dadas por
<prefixo><nome da distribuição> -
Existem 4 prefixos que indicam qual ação será realizada:
d: retorna uma probabilidade a partir de uma função de densidade de probabilidade (pdf)p: retorna uma probabilidade acumulada a partir de uma função de distribuição acumulada (cdf)q: retorna uma estatística da distribuição (quantil) dada uma probabilidade acumuladar: gera números aleatórios dada a distribuição
-
Existem diversas distribuições disponíveis no R:
norm: Normalbern: Bernoulli (pacoteRlab)binom: Binomialpois: Poissonchisq: Qui-Quadrado ( $\chi^2$)t: t-Studentf: Funif: Uniformeweibull: Weibullgamma: Gammalogis: Logísticaexp: Exponencial
-
Seguem as principais distribuições e suas respectivas funções:
| Distribuição | Densidade de Probabilidade | Distribuição Acumulada | Quantil |
|---|---|---|---|
| Normal | dnorm(x, mean, sd) |
pnorm(q, mean, sd) |
qnorm(p, mean, sd) |
| Qui-Quadrado | dchisq(x, df) |
pchisq(q, df) |
qchisq(p, df) |
| t-Student | dt(x, df) |
pt(q, df) |
qt(p, df) |
| F | df(x, df1, df2) |
pf(q, df1, df2) |
qf(p, df1, df2) |
| Binomial | dbinom(x, size, prob) |
pbinom(q, size, prob) |
qbinom(p, size, prob) |
em que x e q são estatísticas de cada distribuição (quantis), e p é probabilidade.
Distribuição Normal
- Considere uma normal padrão, $N(\mu=0, \sigma=1)$, e escores padrão $Z=-1,96 \text{ e } 1,96$ (para intervalo de confiança de $\approx 5\%$):

- [
d]: Densidade a partir de uma pdf, dada estatística (escore padrão):
dnorm(1.96, mean=0, sd=1) # probabilidade para escore padrão de 1,96
## [1] 0.05844094
dnorm(-1.96, mean=0, sd=1) # probabilidade para escore padrão de -1,96
## [1] 0.05844094
- [
p]: Probabilidade acumulada a partir de uma cdf, dada estatística (escore padrão):
pnorm(1.96, mean=0, sd=1) # probabilidade acumulada para escore padrão de 1,96
## [1] 0.9750021
pnorm(-1.96, mean=0, sd=1) # probabilidade acumulada para escore padrão de -1,96
## [1] 0.0249979
Logo, a probabilidade de que uma variável aleatória com distribuição normal padrão esteja com valor entre -1,96 e 1,96 é de 95%
pnorm(1.96, mean=0, sd=1) - pnorm(-1.96, mean=0, sd=1)
## [1] 0.9500042
- [
q]: Estatística (escore padrão) a partir de um quantil:
qnorm(0.975, mean=0, sd=1) # quantil dada o quantil de 97,5%
## [1] 1.959964
qnorm(0.025, mean=0, sd=1) # quantil dada o quantil de 2,5%
## [1] -1.959964
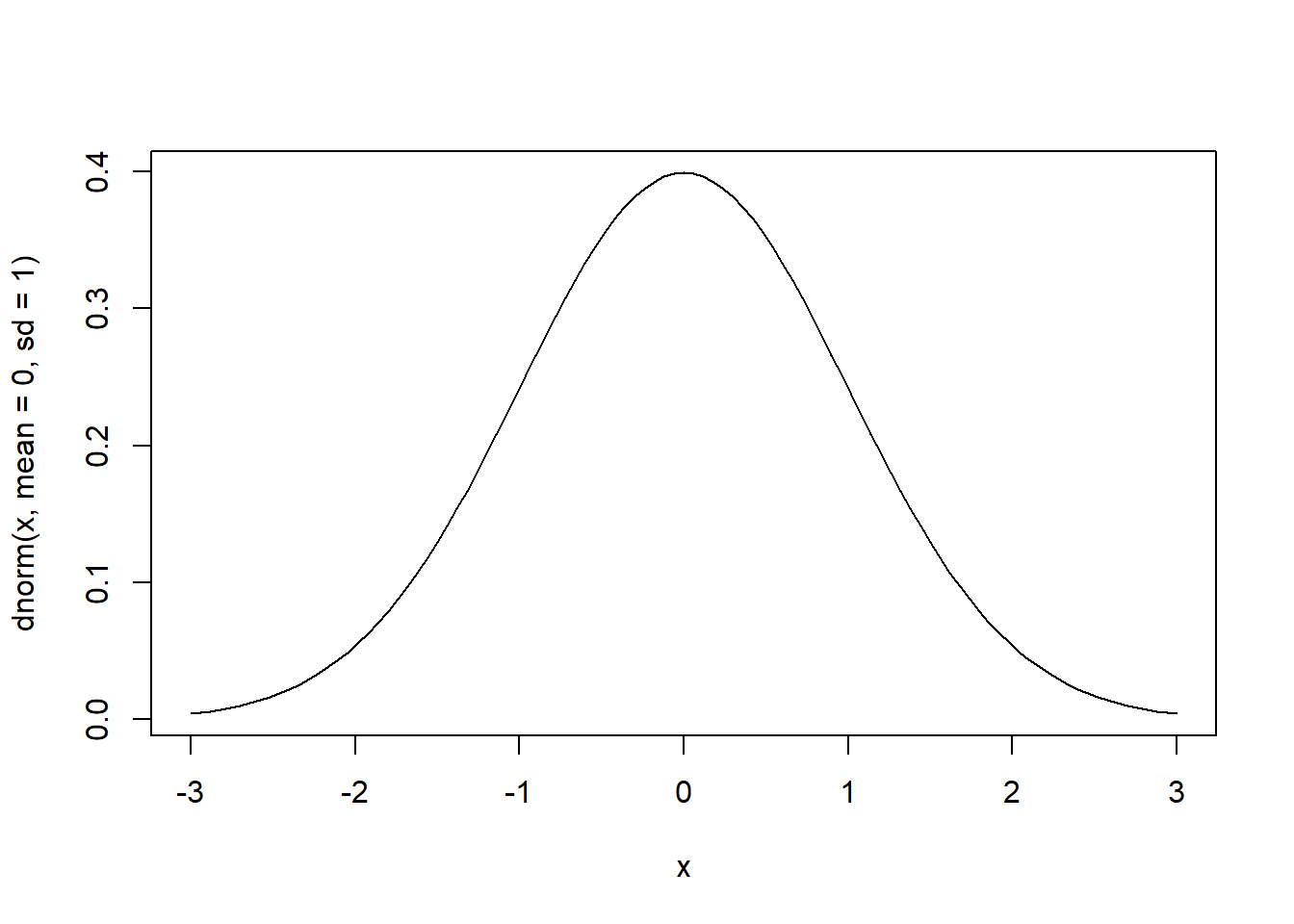
Podemos criar gráficos usando a função curve( function(x), from, to ), na qual inserimos uma função com um x arbitrário e seus limites mínimo e máximo (from e to):
# pdf de normal padrão com estatística (escore padrão) no intervalo -3 e 3
curve(dnorm(x, mean=0, sd=1), from=-3, to=3)
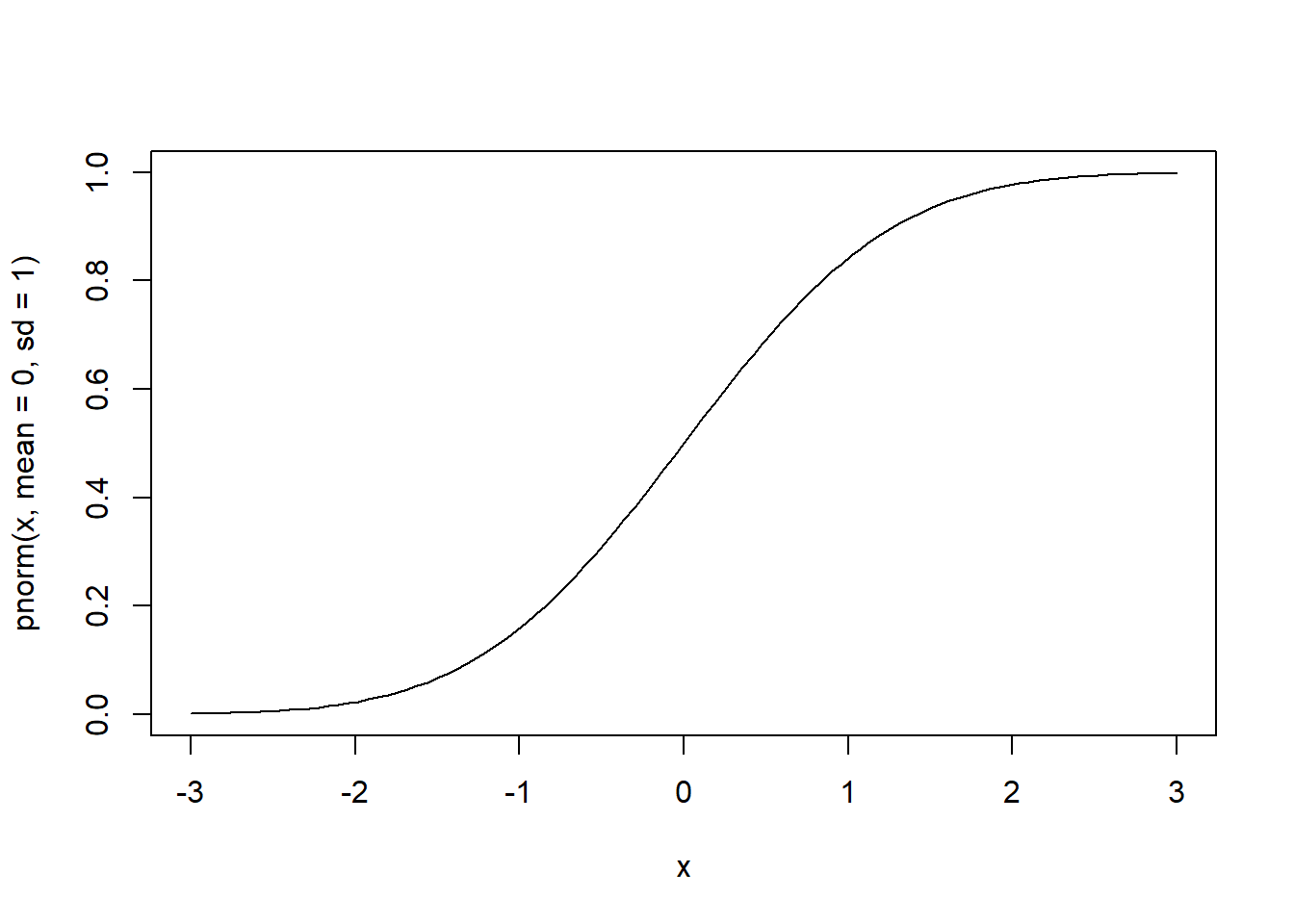
# cdf de normal padrão com estatística (escore padrão) no intervalo -3 e 3
curve(pnorm(x, mean=0, sd=1), from=-3, to=3)
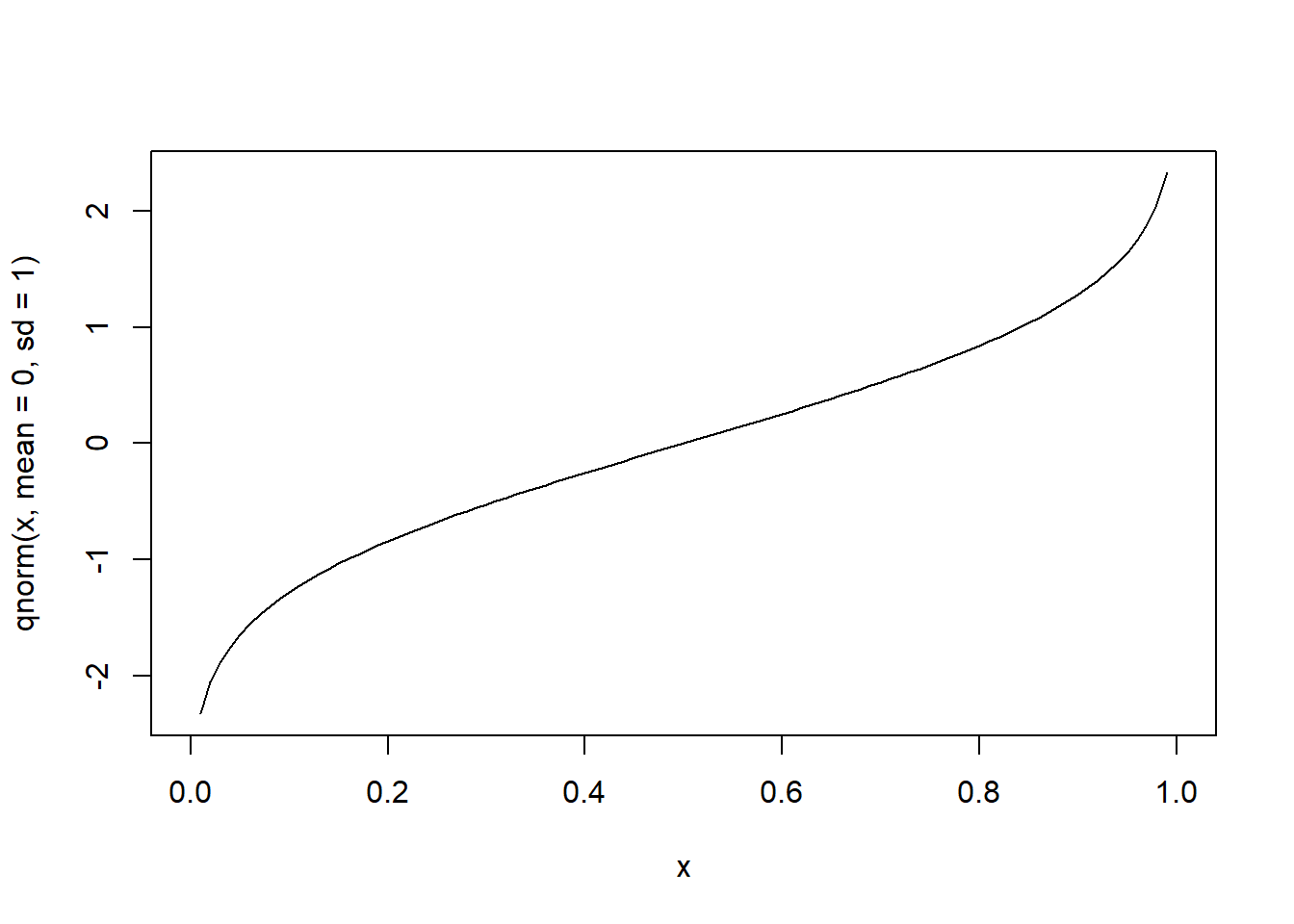
# quantil de normal padrão com probabilidade acumulada no intervalo 0 e 1
curve(qnorm(x, mean=0, sd=1), from=0, to=1)
Distribuição t-Student
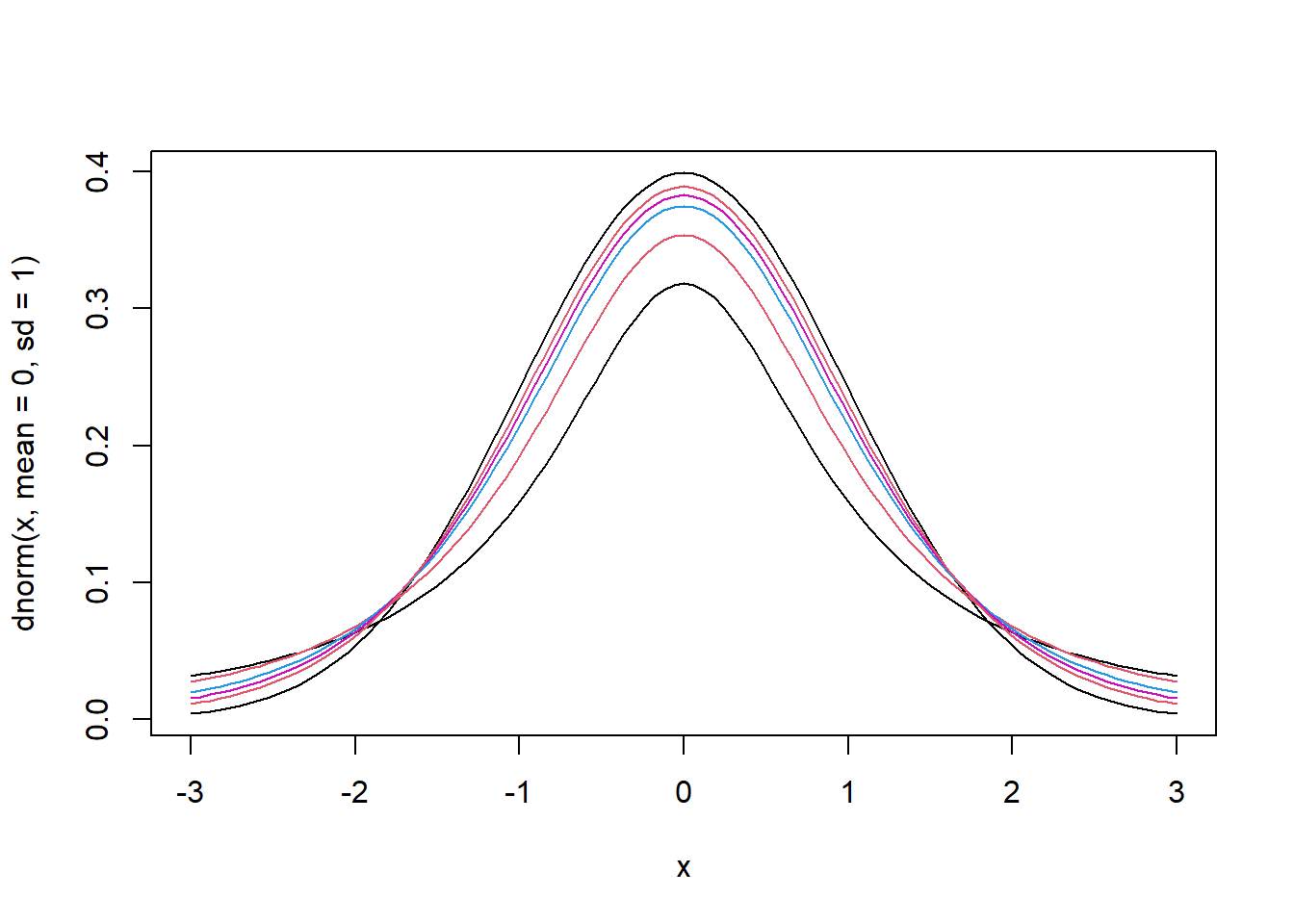
- Criaremos gráficos com diversos graus de liberdade
- Quanto maior os graus de liberdade, mais se aproxima de uma normal padrão
curve(dnorm(x, mean=0, sd=1), from=-3, to=3, pch=".") # pdf normal padrão
for (n in c(1, 2, 4, 6, 10)) {
curve(dt(x, df=n), from=-3, to=3, col=n, add=T) # pdf t-student
}
Distribuição Qui-Quadrado
- Criaremos gráficos com diversos graus de liberdade
curve(dchisq(x, df=1), from=0, to=6, col=n) # pdf qui-quadrado
for (n in c(2:5)) {
curve(dchisq(x, df=n), from=0, to=6, col=n, add=T) # pdf qui-quadrado
}
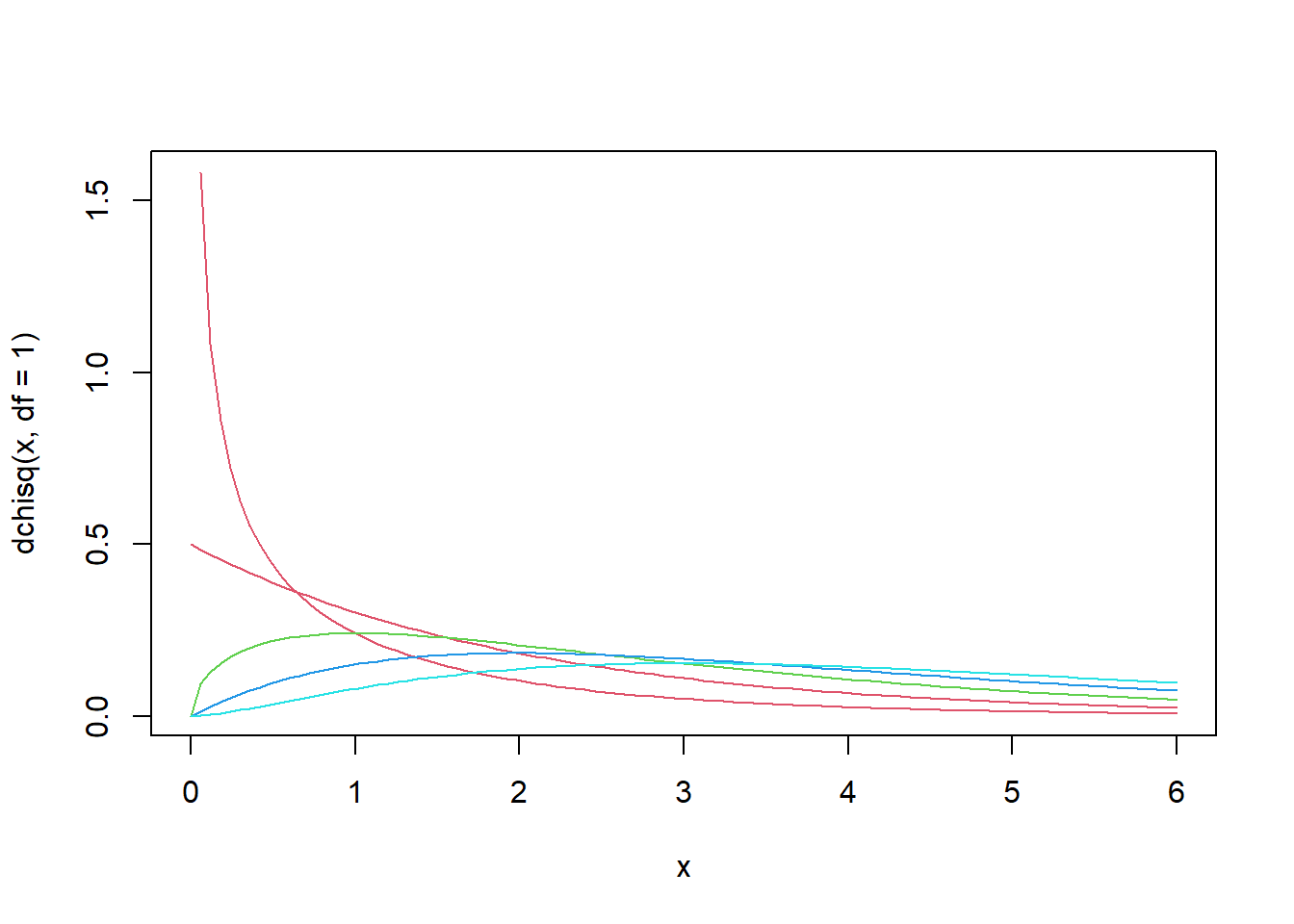
Distribuição F
- Criaremos gráficos com diversos graus de liberdade
curve(df(x, df1=1, df2=1), from=0, to=6, col=n) # pdf F
for (n in c(2:5)) {
curve(df(x, df1=n, df2=n), from=0, to=6, col=n, add=T) # pdf F
}
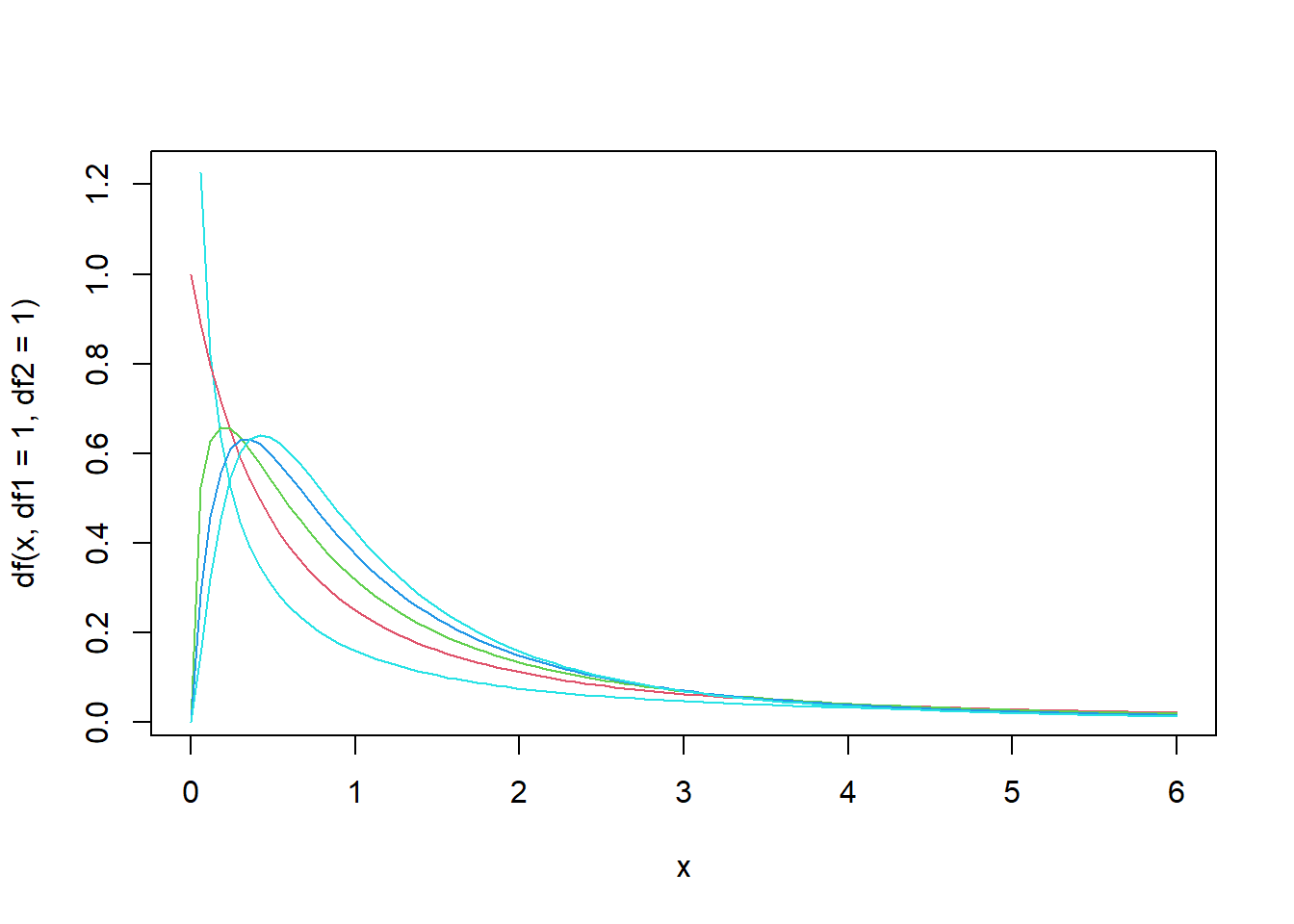
Simulação
Geração de números aleatórios
- Simulation - Random sampling (John Hopkins/Coursera)
- Para gerar números aleatórios, usaremos o prefixo
rjunto de uma distribuição.
rnorm(5) # gerando 5 números aleatórios
## [1] 1.9263422 0.8835259 0.4614015 -0.5351940 -0.2656456
- Para reproduzir resultados que usem números aleatórios, podemos definir “sementes” usando a função
set.seed()e informando um número inteiro. Isso também é válido para a funçãosample().
# definindo seed
set.seed(2022)
rnorm(5)
## [1] 0.9001420 -1.1733458 -0.8974854 -1.4445014 -0.3310136
# sem definir seed
rnorm(5)
## [1] -2.9006290 -1.0592557 0.2779547 0.7494859 0.2415825
# definindo seed
set.seed(2022)
rnorm(5)
## [1] 0.9001420 -1.1733458 -0.8974854 -1.4445014 -0.3310136
Exemplo: Criação de observações x e y
Vamos criar observações da variável $x$ a partir de uma distribuição uniforme no intervalo [0, 10]:
N = 100 # número de observações
x = runif(N, 0, 10) # nº aleatórios a partir de U[0,10]
head(x)
## [1] 0.01862073 1.59799489 1.44741664 5.19396774 6.09476454 1.22510589
Agora, vamos criar a variável $y = 10 - 2x + \varepsilon, \ \varepsilon \sim N(0, 3^2)$ e plotar ambas variáveis em um scatterplot:
e = rnorm(N, mean=0, sd=3)
y = 10 - 2*x + e
plot(x, y) ## scatterplot entre x e y
abline(a=10, b=-2, col="red")
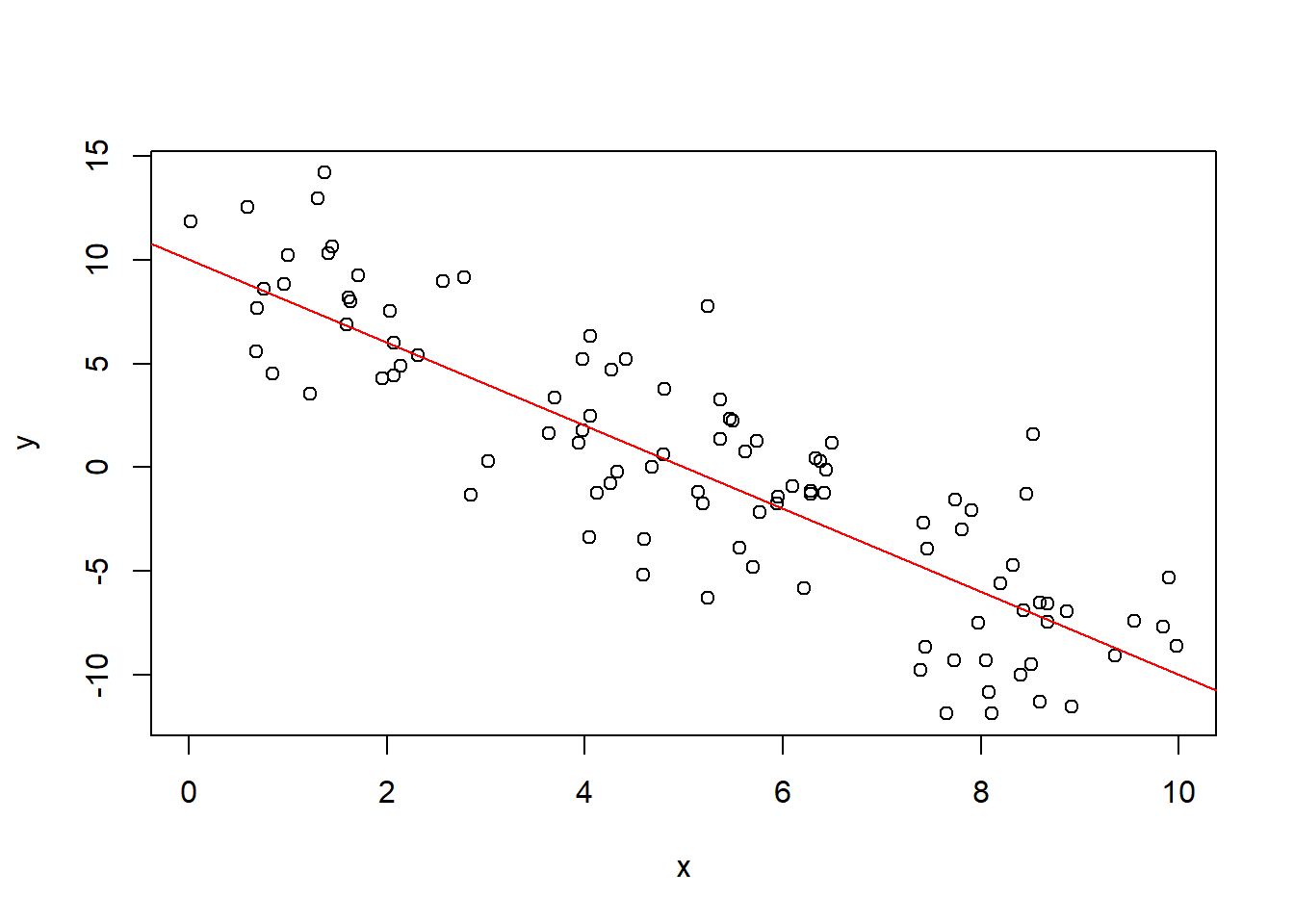
Amostragem aleatória
- Para fazer uma amostragem a partir de um dado vetor, usamos a função
sample()
sample(x, size, replace = FALSE, prob = NULL)
x: either a vector of one or more elements from which to choose, or a positive integer. See ‘Details.’
n: a positive number, the number of items to choose from.
size: a non-negative integer giving the number of items to choose.
replace: should sampling be with replacement?
prob: a vector of probability weights for obtaining the elements of the vector being sampled.
sample(letters, 5) # Amostragem de 5 letras
## [1] "p" "c" "u" "e" "j"
sample(1:10, 4) # Amostragem de 4 números de 1 a 10
## [1] 3 2 1 6
sample(1:10) # Permutação (amostra mesma qtd de elementos do vetor)
## [1] 7 3 5 8 6 4 9 10 2 1
sample(1:10, replace = TRUE) # Amostragem com reposição
## [1] 3 5 4 10 2 9 7 4 10 1
- Note que, por padrão, a função
sample()faz a amostragem sem reposição.
Exemplo: Lei dos Grandes Números (LGN)
- Podemos usar a amostragem para simular jogadas de dado não-viesado.
- Vamos jogar uma vez o dado:
sample(1:6, 1) # amostra um número dentro do vetor 1:6
## [1] 2
- Vamos jogar 1000 vezes o dado (usando função
replicate()) e verificar sua distribuição:
amostra = replicate(1000, expr=sample(1:6, 1))
table(amostra) # tabela com contagem das jogadas
## amostra
## 1 2 3 4 5 6
## 165 173 161 153 165 183
# Gráfico
plot(table(amostra), type="h")
 - Note que não podemos usar a função `rep()` com simulação, pois ele sortearia um número e replicaria esse mesmo número 1000 vezes.
- Agora, vamos jogar 2 vezes o dado e fazer a média entre eles
- Note que não podemos usar a função `rep()` com simulação, pois ele sortearia um número e replicaria esse mesmo número 1000 vezes.
- Agora, vamos jogar 2 vezes o dado e fazer a média entre eles
mean(sample(1:6, 2))
## [1] 2.5
- Fazendo isso 1000 vezes, temos:
amostra = replicate(1000, mean(sample(1:6, 2, replace=T)))
table(amostra) # tabela com contagem das médias de 2 jogadas
## amostra
## 1 1.5 2 2.5 3 3.5 4 4.5 5 5.5 6
## 33 51 72 105 138 192 122 104 78 68 37
# Gráfico
plot(table(amostra), type="h")
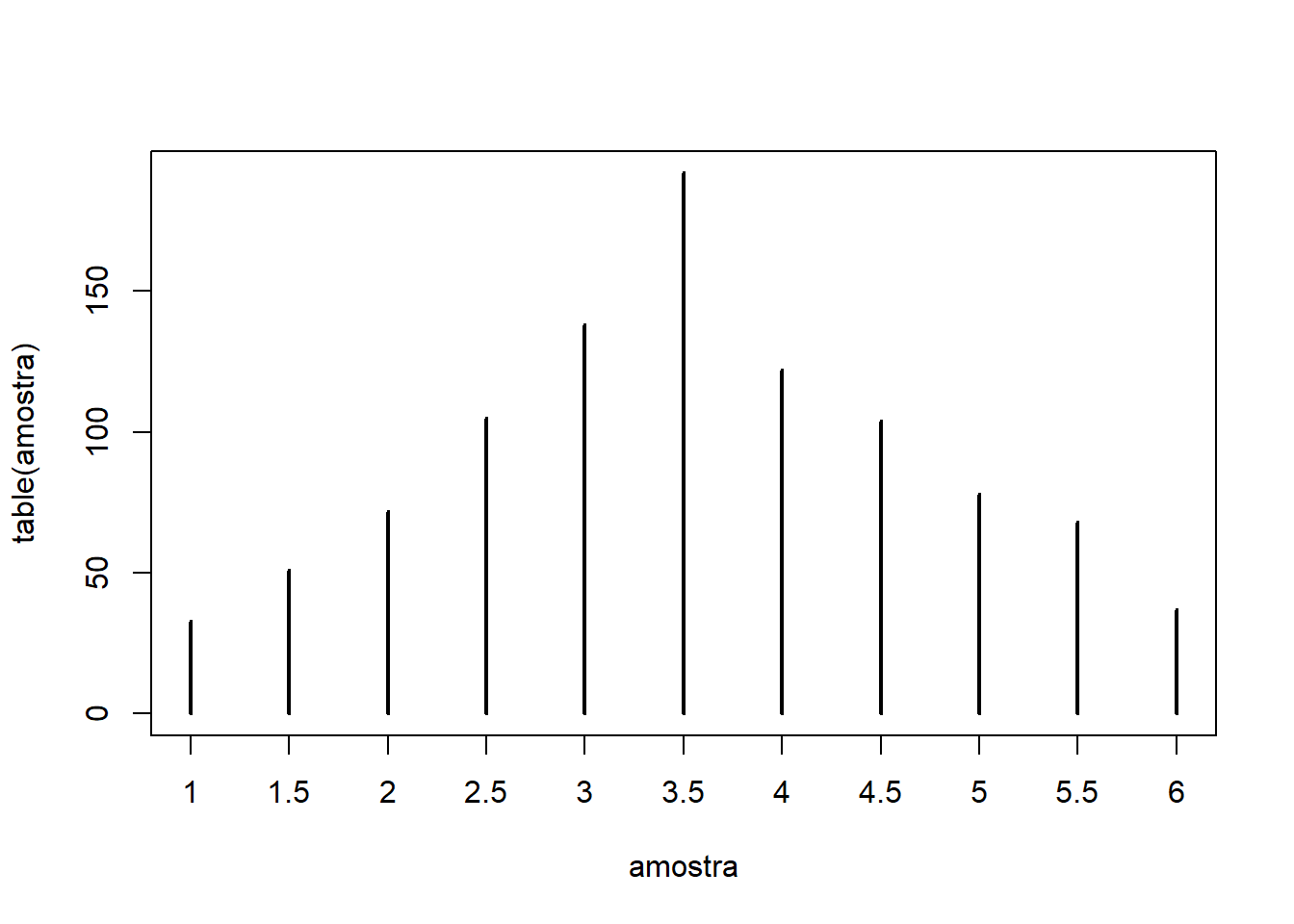
- Note que, ao repetir 1000 vezes, o cálculo da média de 2 jogadas de dado, começou a dar mais peso para médias próximas à média populacional (3,5), mas ainda tem densidade nos valores mais extremos (1 e 6)
- Foi necessário usar o argumento
replace=TRUEpara ter “reposição” dos números do dado - Calculando 1000 vezes a média de $N=100$ jogadas de dado, temos:
N = 100 # nº de observações
amostra = replicate(1000, mean(sample(1:6, N, replace=T)))
# Gráfico
plot(table(amostra), type="h", xlim=c(1,6))
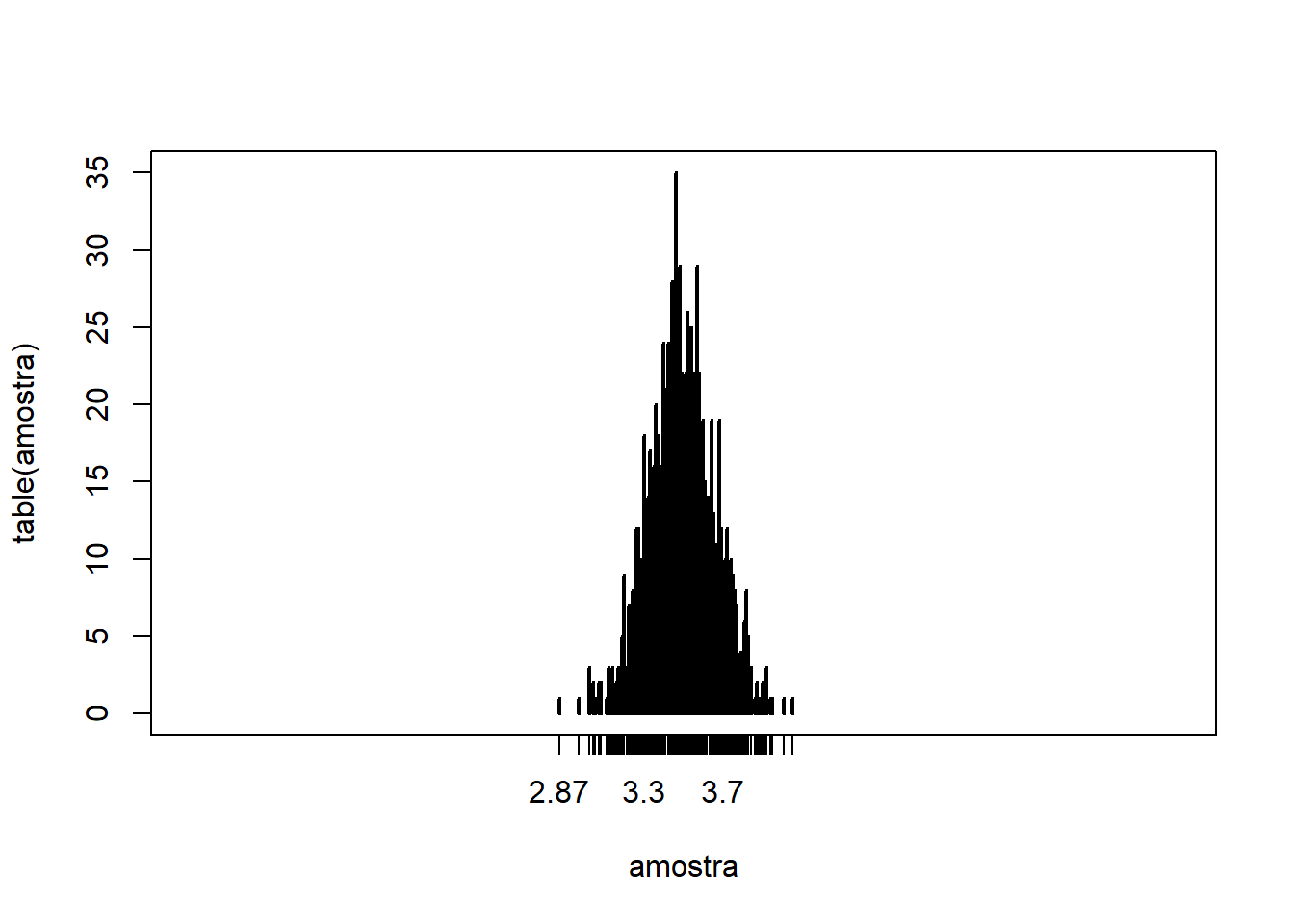
- Note que, quanto maior $N$, a distribuição das médias vai se degenerando, tendo maior concentração na proximidade da média populacional (3,5), e sendo praticamente nula em médias mais distantes.