- Seções 8.2 e 8.3 de Heiss (2020)
- Seções 5.5, 7.1 a 7.4 de Davidson e MacKinnon (1999)
- Seções 4.2.3 e 4.2.4 de Wooldridge
Matriz de variâncias-covariâncias dos erros
Relembre que a matriz de variâncias-covariâncias dos erros é dada por:
$$ cov(\boldsymbol{\varepsilon}) = \underset{N \times N}{\boldsymbol{\Sigma}} = \left[ \begin{array}{cccc} var(\varepsilon_{1}) & cov(\varepsilon_{1}, \varepsilon_{2}) & \cdots & cov(\varepsilon_{1}, \varepsilon_{N}) \\ cov(\varepsilon_{2}, \varepsilon_{1}) & var(\varepsilon_{2}) & \cdots & cov(\varepsilon_{2}, \varepsilon_{N}) \\ \vdots & \vdots & \ddots & \vdots \\ cov(\varepsilon_{N}, \varepsilon_{1}) & cov(\varepsilon_{N}, \varepsilon_{2}) & \cdots & var(\varepsilon_{N}) \end{array} \right]$$Como assumimos amostragem aleatória, a covariância entre dois indivíduos distintos
($i \neq j$) é
$$ cov(\varepsilon_{i}, \varepsilon_{j}) = 0, \qquad \text{para todo } i \neq j.$$
Logo, $$ \boldsymbol{\Sigma} = \left[ \begin{array}{cccc} var(\varepsilon_{1}) & 0 & \cdots & 0 \\ 0 & var(\varepsilon_{2}) & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & var(\varepsilon_{N}) \end{array} \right]$$
Para MQO, assumíamos homocedasticidade e, portanto, a diagonal principal era toda preenchida por um mesmo $ var(\varepsilon_i) = \sigma^2,\ \forall i$. Na presença de heteroscedasticidade, segue que $ var(\varepsilon_i) = \sigma^2_i,\ \forall i$ e, logo:
$$ \boldsymbol{\Sigma} = \left[ \begin{array}{cccc} \sigma^2_1 & 0 & \cdots & 0 \\ 0 & \sigma^2_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \sigma^2_N \end{array} \right] \ \neq\ \sigma^2 I_N $$Como é uma matriz diagonal, é fácil computar a inversa da matriz:
$$ \boldsymbol{\Sigma}^{-1} = \left[ \begin{array}{cccc} 1/\sigma^2_1 & 0 & \cdots & 0 \\ 0 & 1/\sigma^2_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 1/\sigma^2_N \end{array} \right]$$ e $$\boldsymbol{\Sigma}^{-0.5} = \left[ \begin{array}{cccc} 1/\sigma_1 & 0 & \cdots & 0 \\ 0 & 1/\sigma_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 1/\sigma_N \end{array} \right]$$
Testes de heterocedasticidade
- A ideia os testes de heterocedasticidade é pegar os resíduos da estimação por MQO, $\hat{\boldsymbol{\varepsilon}}$, e verificar sua correlação com as variáveis explicativas, $\boldsymbol{X}$. Em caso de homocedasticidade, essa correlação deveria ser estatisticamente nula.
- Podemos testar isso por meio do testes de Breusch-Pagan ou de White.
Teste de Breusch-Pagan
-
Inicialmente, considere o seguinte modelo linear $$\boldsymbol{y} = \beta_0 + \beta_1 \boldsymbol{x}_{1} + ... + \beta_K \boldsymbol{x}_{K} + \boldsymbol{\varepsilon} = \boldsymbol{X} \boldsymbol{\beta} + \boldsymbol{\varepsilon} $$
-
Ao estimá-lo por MQO, obtemos os resíduos $\hat{\boldsymbol{\varepsilon}} = \boldsymbol{y} - \hat{\boldsymbol{y}} = \boldsymbol{y} - \boldsymbol{X} \hat{\boldsymbol{\beta}}$
-
Depois, fazemos a regressão dos resíduos ao quadrado em função das covariadas: $$\hat{\boldsymbol{\varepsilon}}^2 = \alpha + \gamma_1 \boldsymbol{x}_{1} + ... + \gamma_K \boldsymbol{x}_{K} + \boldsymbol{u} = \boldsymbol{X} \boldsymbol{\gamma} + \boldsymbol{u} $$
-
Breusch-Pagan (1979) e Koenker (1981) propuseram testar a hipótese nula conjunta de que todos os parâmetros são iguais a zero: $$H_0: \quad \boldsymbol{\gamma} = \boldsymbol{0} \iff \begin{bmatrix} \gamma_1 \\ \gamma_2 \\ \vdots \\ \gamma_K \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \\ \vdots \\ 0 \end{bmatrix} $$
-
A verificação dessa hipótese pode ser feita via estatística LM
Exemplo 8.7: Demanda por Cigarros (Wooldridge)
-
Nesta seção, vamos usar a base de dados
smokedo pacotewooldridgepara estimar o seguinte modelo: \begin{align}\text{cigs} = &\beta_0 + \beta_1 \text{lincome} + \beta_2 \text{lcigpric} + \beta_3 \text{educ} + \beta_4 \text{age}\\ &+ \beta_5 \text{agesq} + \beta_6 \text{restaurn} + \varepsilon \end{align} em que: -
cigs: cigarros fumados por dia
-
lincome: log da renda
-
lcigpric: log do preço do cigarro
-
educ: anos de escolaridade
-
age: idade
-
agesq: idade ao quadrado
-
restaurn: dummy resturante tem restrições de fumo
library(lmtest) # precisa ser instalado
data(smoke, package="wooldridge")
# Regressão do modelo
reg = lm(cigs ~ lincome + lcigpric + educ + age + agesq + restaurn, data=smoke)
bptest(reg)
##
## studentized Breusch-Pagan test
##
## data: reg
## BP = 32.258, df = 6, p-value = 1.456e-05
# Teste BP na "mão"
N = nrow(smoke)
K = ncol(model.matrix(reg)) - 1
reg.resid = lm(resid(reg)^2 ~ lincome + lcigpric + educ + age + agesq + restaurn,
data=smoke)
r2e = summary(reg.resid)$r.squared
LM = N * r2e
1 - pchisq(LM, K)
## [1] 1.455779e-05
- Alternativamente, o teste também pode ser feito pela estatística LM (ou, também, Wald): $$ F_{\scriptscriptstyle{K, (N-K-1)}} = \frac{R^2_{\scriptstyle{\hat{\varepsilon}}}/K}{(1 - R^2_{\scriptstyle{\hat{\varepsilon}}}) / (N-K-1)} $$
# Teste F já vem calculado no summary(lm())
summary(reg.resid)
##
## Call:
## lm(formula = resid(reg)^2 ~ lincome + lcigpric + educ + age +
## agesq + restaurn, data = smoke)
##
## Residuals:
## Min 1Q Median 3Q Max
## -270.1 -127.5 -94.0 -39.1 4667.8
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -636.30306 652.49456 -0.975 0.3298
## lincome 24.63848 19.72180 1.249 0.2119
## lcigpric 60.97655 156.44869 0.390 0.6968
## educ -2.38423 4.52753 -0.527 0.5986
## age 19.41748 4.33907 4.475 8.75e-06 ***
## agesq -0.21479 0.04723 -4.547 6.27e-06 ***
## restaurn -71.18138 30.12789 -2.363 0.0184 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 363.2 on 800 degrees of freedom
## Multiple R-squared: 0.03997, Adjusted R-squared: 0.03277
## F-statistic: 5.552 on 6 and 800 DF, p-value: 1.189e-05
# Teste F na "mão"
F = (r2e / K) / ((1-r2e) / (N-K-1))
F
## [1] 5.551687
1 - pf(F, K, N-K-1)
## [1] 1.188811e-05
- Note que os testes avaliam se há heterocedasticidade, mas não mostra quais variáveis são responsáveis por isso.
- Por isso, pode ser interessante também visualizar os testes t de cada regressor na regressão sobre o quadrado do resíduos. Neste caso, aparenta ocorrer pela variável age, agesq e restaurn.
Teste de White
- Embora o teste de Breusch-Pagan seja interessante, ele avalia os erros apenas de forma linear nas variáveis explicativas: $$\hat{\boldsymbol{\varepsilon}}^2 = \alpha + \gamma_1 \boldsymbol{x}_{1} + ... + \gamma_K \boldsymbol{x}_{K} + \boldsymbol{u}$$
- Portanto, para capturar mais formas de heterocedasticidade, é interessante colocar também as interações entre os regressores e seus quadrados na forma: \begin{align} \hat{\boldsymbol{\varepsilon}}^2 = & \alpha + {\color{blue}\gamma_1 \boldsymbol{x}_{1} + ... + \gamma_K \boldsymbol{x}_{K}} + {\color{red}\delta_{11} \boldsymbol{x}^2_{1} + \delta_{12} (\boldsymbol{x}_{1}\boldsymbol{x}_{2}) + ... + \delta_{1K} (\boldsymbol{x}_{1}\boldsymbol{x}_{K})}\\ & {\color{red}+ \delta_{22} \boldsymbol{x}^2_{2} + \delta_{23} (\boldsymbol{x}_{2}\boldsymbol{x}_{3}) + ... + \delta_{KK}\boldsymbol{x}^2_{K}} + \boldsymbol{u} \end{align}
- Então, o teste de hipótese seria: $$H_0: \quad \begin{bmatrix}\boldsymbol{\gamma} \\ \boldsymbol{\delta} \end{bmatrix} = \boldsymbol{0} \iff \begin{bmatrix} \gamma_1 \\ \gamma_2 \\ \vdots \\ \gamma_K \\ \delta_{11} \\ \delta_{12} \\ \vdots \\ \delta_{KK} \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \\ \vdots \\ 0 \\ 0 \\ 0 \\ \vdots \\ 0 \end{bmatrix} $$
- O problema é que se perdem muitos graus de liberdade quando incluímos parâmetros para todas as interações e os quadrados dos regressores.
- White (1980) então mostrou que é possível fazer um teste equivalente incluindo apenas $\hat{\boldsymbol{y}}$ e $\hat{\boldsymbol{y}}^2$ como regressores no modelo do resíduo ao quadrado: $$\hat{\boldsymbol{\varepsilon}}^2 = \alpha + {\color{blue}\gamma \hat{\boldsymbol{y}}} + {\color{red}\delta \hat{\boldsymbol{y}}^2} + \boldsymbol{u}$$
- E o teste de hipótese se torna apenas $$H_0: \quad \begin{bmatrix}\gamma \\ \delta \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix} $$ que também pode ser testada pelas estatísticas LM (Breusch-Pagan) ou F.
# Valores ajustados
yhat = fitted(reg)
# Teste via bptest()
bptest(reg, ~ yhat + I(yhat^2))
##
## studentized Breusch-Pagan test
##
## data: reg
## BP = 26.573, df = 2, p-value = 1.698e-06
# Teste BP/LM "na mão"
reg.resid = lm(resid(reg)^2 ~ yhat + I(yhat^2), data=smoke)
r2e = summary(reg.resid)$r.squared
LM = N * r2e
1 - pchisq(LM, 2)
## [1] 1.697606e-06
Estimador MQO com erros padrão robustos
- O estimador de MQO permanece não-viesado/consistente sob heterocedasticidade, mas perde eficiência.
- Um forma de contornar esse problema é modelarmos a matriz de variâncias-covariâncias dos erros $\boldsymbol{\Sigma}$
- Primeiro, lembre-se que a matriz de variâncias-covariâncias do estimador de MQO é dada por $$V(\hat{\boldsymbol{\beta}}) = (\boldsymbol{X}' \boldsymbol{X})^{-1} \boldsymbol{X}' \boldsymbol{\Sigma} \boldsymbol{X} (\boldsymbol{X}' \boldsymbol{X})^{-1}$$
- Como há heterocedasticidade, essa matriz não se simplifica para $V(\hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQO}}) = \sigma^2 (\boldsymbol{X}' \boldsymbol{X})^{-1}$, porém também não conhecemos $\boldsymbol{\Sigma}$, que precisa ser estimado.
- A forma mais simples de obter $\hat{\boldsymbol{\Sigma}}$ foi sugerido por White (1980), que é preencher sua diagonal com o quadrado do resíduo de cada indivíduo (obtido por estimação MQO): $$\hat{\boldsymbol{\Sigma}} = \begin{bmatrix} \hat{\varepsilon}^2_1 & 0 & \cdots & 0 \\ 0 & \hat{\varepsilon}^2_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \hat{\varepsilon}^2_N \end{bmatrix}$$
- Portanto, temos o estimador de matriz de covariâncias consistente com heterocedasticidade (HCCME) $$V(\hat{\boldsymbol{\beta}}) = (\boldsymbol{X}' \boldsymbol{X})^{-1} \boldsymbol{X}' \hat{\boldsymbol{\Sigma}} \boldsymbol{X} (\boldsymbol{X}' \boldsymbol{X})^{-1}$$ que é também é conhecido como estimador sanduíche, pois $(\boldsymbol{X}' \boldsymbol{X})^{-1}$ está nos extremos da fórmula (pão/bread), que “sanduicham” o termo $\boldsymbol{X}' \hat{\boldsymbol{\Sigma}} \boldsymbol{X}$ (carne/meat).
Estimação via lm() e vcovHC()
# Usando fórmula vcovHC() do pacote sandwich
library(lmtest)
library(sandwich) # precisa ser instalado
# Regressão do modelo
reg = lm(cigs ~ lincome + lcigpric + educ + age + agesq + restaurn, data=smoke)
# Construindo matriz vcov do estimador ajustado por heterocedasticidade
vcov_sandwich = vcovHC(reg, type="HC0")
round(vcov_sandwich, 3)
## (Intercept) lincome lcigpric educ age agesq restaurn
## (Intercept) 650.511 -2.642 -149.814 -0.240 -0.489 0.005 3.823
## lincome -2.642 0.352 0.009 -0.029 -0.019 0.000 -0.077
## lcigpric -149.814 0.009 36.110 0.048 0.078 -0.001 -0.783
## educ -0.240 -0.029 0.048 0.026 -0.001 0.000 -0.012
## age -0.489 -0.019 0.078 -0.001 0.019 0.000 -0.002
## agesq 0.005 0.000 -0.001 0.000 0.000 0.000 0.000
## restaurn 3.823 -0.077 -0.783 -0.012 -0.002 0.000 1.007
# Resultados
round(coeftest(reg), 3) # resultado padrão do MQO
##
## t test of coefficients:
##
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -3.640 24.079 -0.151 0.880
## lincome 0.880 0.728 1.210 0.227
## lcigpric -0.751 5.773 -0.130 0.897
## educ -0.501 0.167 -3.002 0.003 **
## age 0.771 0.160 4.813 <2e-16 ***
## agesq -0.009 0.002 -5.176 <2e-16 ***
## restaurn -2.825 1.112 -2.541 0.011 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
round(coeftest(reg, vcov=vcov_sandwich), 3) # resultado com correção
##
## t test of coefficients:
##
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -3.640 25.505 -0.143 0.887
## lincome 0.880 0.593 1.483 0.138
## lcigpric -0.751 6.009 -0.125 0.901
## educ -0.501 0.162 -3.102 0.002 **
## age 0.771 0.138 5.598 <2e-16 ***
## agesq -0.009 0.001 -6.198 <2e-16 ***
## restaurn -2.825 1.004 -2.815 0.005 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
- Note que, neste caso, os erros padrão foram pouco alterados com o ajuste.
- Para ter ganho em eficiência,
$\hat{\boldsymbol{\Sigma}}$ precisa ser bem especificado. Há também outras formas de modelar
$\hat{\boldsymbol{\Sigma}}$ na própria função
vcovHC().
Estimação Analítica
- Também podemos fazer a inferência robusta a heterocedasticidade analiticamente:
# Criando o vetor y
y = as.matrix(smoke[,"cigs"]) # transformando coluna de data frame em matriz
# Criando a matriz de covariadas X com primeira coluna de 1's
X = as.matrix( cbind(1, smoke[,c("lincome", "lcigpric", "educ", "age", "agesq",
"restaurn")]) ) # juntando 1's com x
# Pegando valores N e K
N = nrow(X)
K = ncol(X) - 1
# Estimativas MQO, valores preditos e resíduos
bhat = solve(t(X) %*% X) %*% t(X) %*% y
yhat = X %*% bhat
ehat = y - yhat
head(ehat^2)
## [,1]
## 1 106.770712
## 2 115.665513
## 3 59.596771
## 4 105.280775
## 5 56.312306
## 6 5.950747
- Agora vamos estimar a matriz de variâncias-covariâncias dos erros pelo método de White, preenchendo a sua diagonal com os resíduos ao quadrado para cada indivíduo: $$\hat{\boldsymbol{\Sigma}} = diag(\hat{\varepsilon}_1, \hat{\varepsilon}_2, ..., \hat{\varepsilon}_N) = \begin{bmatrix} \hat{\varepsilon}^2_1 & 0 & \cdots & 0 \\ 0 & \hat{\varepsilon}^2_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \hat{\varepsilon}^2_N \end{bmatrix}$$
# Estimando matriz de vcov dos erros (diagonal com resíduo^2 de cada indiv)
Sigma = diag(as.numeric(ehat^2)) # transformar em numeric p/ preencher diagonal
round(Sigma[1:7, 1:7], 3)
## [,1] [,2] [,3] [,4] [,5] [,6] [,7]
## [1,] 106.771 0.000 0.000 0.000 0.000 0.000 0.000
## [2,] 0.000 115.666 0.000 0.000 0.000 0.000 0.000
## [3,] 0.000 0.000 59.597 0.000 0.000 0.000 0.000
## [4,] 0.000 0.000 0.000 105.281 0.000 0.000 0.000
## [5,] 0.000 0.000 0.000 0.000 56.312 0.000 0.000
## [6,] 0.000 0.000 0.000 0.000 0.000 5.951 0.000
## [7,] 0.000 0.000 0.000 0.000 0.000 0.000 142.419
- Note que foi necessário transformar
ehat^2em numeric para aplicar o operadordiag(). Caso não fosse feito, iria retornar um número ao invés de criar uma matriz diagonal preenchida com os resíduos ao quadrado. - Agora, o podemos estimar a matriz de variâncias-covariâncias do estimador robusta a heterocedasticidade: $$V(\hat{\boldsymbol{\beta}}) = (\boldsymbol{X}' \boldsymbol{X})^{-1} \boldsymbol{X}' \hat{\boldsymbol{\Sigma}} \boldsymbol{X} (\boldsymbol{X}' \boldsymbol{X})^{-1}$$
# Matriz de variâncias-covariância do estimador
bread = solve(t(X) %*% X)
meat = t(X) %*% Sigma %*% X
Vbhat = bread %*% meat %*% bread
round(Vbhat, 3)
## 1 lincome lcigpric educ age agesq restaurn
## 1 650.511 -2.642 -149.814 -0.240 -0.489 0.005 3.823
## lincome -2.642 0.352 0.009 -0.029 -0.019 0.000 -0.077
## lcigpric -149.814 0.009 36.110 0.048 0.078 -0.001 -0.783
## educ -0.240 -0.029 0.048 0.026 -0.001 0.000 -0.012
## age -0.489 -0.019 0.078 -0.001 0.019 0.000 -0.002
## agesq 0.005 0.000 -0.001 0.000 0.000 0.000 0.000
## restaurn 3.823 -0.077 -0.783 -0.012 -0.002 0.000 1.007
- Só falta calcular os erros padrão, estísticas t e p-valores:
# Erro padrão robusto, estat t e p-valor
se = sqrt(diag(Vbhat))
t = bhat / se
p = 2 * pt(-abs(t), N-K-1)
# Resultados
round(data.frame(bhat, se, t, p), 3) # resultado obtido analiticamente
## bhat se t p
## 1 -3.640 25.505 -0.143 0.887
## lincome 0.880 0.593 1.483 0.138
## lcigpric -0.751 6.009 -0.125 0.901
## educ -0.501 0.162 -3.102 0.002
## age 0.771 0.138 5.598 0.000
## agesq -0.009 0.001 -6.198 0.000
## restaurn -2.825 1.004 -2.815 0.005
round(coeftest(reg, vcov=vcov_sandwich), 3) # obtido por funções
##
## t test of coefficients:
##
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -3.640 25.505 -0.143 0.887
## lincome 0.880 0.593 1.483 0.138
## lcigpric -0.751 6.009 -0.125 0.901
## educ -0.501 0.162 -3.102 0.002 **
## age 0.771 0.138 5.598 <2e-16 ***
## agesq -0.009 0.001 -6.198 <2e-16 ***
## restaurn -2.825 1.004 -2.815 0.005 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Estimador MQG
-
Alternativamente, podemos fazer a estimação e a inferência modelando a matriz de variâncias-covariâncias dos erros, $\boldsymbol{\Sigma}$.
-
O estimador de Mínimos Quadrados Generalizados (MQG/GLS), assumindo dados em corte transversal, é dado por $$ {\hat{\boldsymbol{\beta}}}_{\scriptscriptstyle{MQG}} = (\boldsymbol{X}' {\boldsymbol{\Sigma}}^{-1} \boldsymbol{X})^{-1} (\boldsymbol{X}' {\boldsymbol{\Sigma}}^{-1} \boldsymbol{y}) $$
-
A matriz de variâncias-covariâncias do estimador é dada por $$ V(\hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQG}}) = (\boldsymbol{X}' \boldsymbol{\Sigma}^{-1} \boldsymbol{X})^{-1} $$
-
O problema é que desconhecemos $\boldsymbol{\Sigma}$, e precisamos fazer mais premissas sobre a forma da matriz de variâncias-covariâncias dos erros (e sua inversa) para estimar $\boldsymbol{\hat{\Sigma}}$.
Estimador MQP
-
Um caso especial de MQG é o estimador de Mínimos Quadrados Ponderados (MQP/WLS), que considera que a variância do erro de cada observação é conhecida e proporcional a das demais.
-
A variância do erro individual é a partir uma função das variáveis explicativas, $h(\boldsymbol{x}'_i)$: $$ Var(\varepsilon_i | \boldsymbol{x}'_i) = \sigma^2.h(\boldsymbol{x}'_i), $$ ou seja, \begin{align} \boldsymbol{\Sigma} &= \left[ \begin{array}{cccc} \sigma^2 h(\boldsymbol{x}'_1) & 0 & \cdots & 0 \\ 0 & \sigma^2 h(\boldsymbol{x}'_2) & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \sigma^2 h(\boldsymbol{x}'_1) \end{array} \right] \\ &= \sigma^2 \left[ \begin{array}{cccc} h(\boldsymbol{x}'_1) & 0 & \cdots & 0 \\ 0 & h(\boldsymbol{x}'_2) & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & h(\boldsymbol{x}'_N) \end{array} \right] \\ &\equiv \sigma^2 \boldsymbol{W}^{-1} \end{align} em que $\boldsymbol{W}$ é uma matriz de pesos: $$ \boldsymbol{W} = \left[ \begin{array}{cccc} \frac{1}{h(\boldsymbol{x}'_1)} & 0 & \cdots & 0 \\ 0 & \frac{1}{h(\boldsymbol{x}'_2)} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \frac{1}{h(\boldsymbol{x}'_N)} \end{array} \right] \equiv \left[ \begin{array}{cccc} w_1 & 0 & \cdots & 0 \\ 0 & w_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & w_N \end{array} \right] $$ em que $w_i$ são os pesos da estimação.
-
Por exemplo, considere que a variância das mulheres é o dobro da variância dos homens ( $\sigma^2_M = 2.\sigma^2_H $), então: $$ h(\text{female}_i) = \left\{ \begin{matrix} 2, &\text{se female}_i = 1 \\ 1, &\text{se female}_i = 0 \end{matrix} \right. $$
-
Considerando que as $M$ primeiras linhas são de mulheres, a matriz de variâncias-covariâncias dos erros pode ser simplificada para: \begin{align} \boldsymbol{\Sigma} &= \left[ \begin{array}{cccc} \sigma^2_M & \cdots & 0 & 0 & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & \sigma^2_M & 0 & \cdots & 0 \\ 0 & \cdots & 0 & \sigma^2_H & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & 0 & 0 & \cdots & \sigma^2_H \\ \end{array} \right] \\ &= \left[ \begin{array}{cccc} 2\sigma^2 & \cdots & 0 & 0 & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & 2\sigma^2 & 0 & \cdots & 0 \\ 0 & \cdots & 0 & \sigma^2 & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & 0 & 0 & \cdots & \sigma^2 \\ \end{array} \right] \\ &= \left[ \begin{array}{cccc} 2\sigma^2 & \cdots & 0 & 0 & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & 2\sigma^2 & 0 & \cdots & 0 \\ 0 & \cdots & 0 & \sigma^2 & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & 0 & 0 & \cdots & \sigma^2 \\ \end{array} \right] \\ &= \sigma^2 \left[ \begin{array}{cccc} 2 & \cdots & 0 & 0 & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & 2 & 0 & \cdots & 0 \\ 0 & \cdots & 0 & 1 & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & 0 & 0 & \cdots & 1 \\ \end{array} \right] \end{align}
-
Por ser uma matriz diagonal, as seguintes matrizes são facilmente calculadas: $$ \boldsymbol{\Sigma}^{-1} = \frac{1}{\sigma^2} \left[ \begin{array}{cccc} \frac{1}{2} & \cdots & 0 & 0 & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & \frac{1}{2} & 0 & \cdots & 0 \\ 0 & \cdots & 0 & \frac{1}{1} & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & 0 & 0 & \cdots & \frac{1}{1} \\ \end{array} \right] \equiv \frac{1}{\sigma^2} \boldsymbol{W}, $$ e $$ \boldsymbol{\Sigma}^{-0.5} = \frac{1}{\sigma} \left[ \begin{array}{cccc} \frac{1}{\sqrt{2}} & \cdots & 0 & 0 & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & \frac{1}{\sqrt{2}} & 0 & \cdots & 0 \\ 0 & \cdots & 0 & \frac{1}{\sqrt{1}} & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & 0 & 0 & \cdots & \frac{1}{\sqrt{1}} \\ \end{array} \right] \equiv \frac{1}{\sigma} \boldsymbol{W}^{0.5} $$
- Disto, podemos obter o estimador $\hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQP}}$:
- A matriz de variâncias-covariâncias do estimador de MQP é dada por
- A variância dos erros, $\sigma^2$, pode ser estimada usando: $$ \hat{\sigma}^2 = \frac{\hat{\boldsymbol{\varepsilon}}' \boldsymbol{W} \hat{\boldsymbol{\varepsilon}}}{N-K-1} $$
-
Também podemos transformar as variáveis e resolver por MQO, pré-multiplicando $\boldsymbol{X}$ e $\boldsymbol{y}$ por $ \boldsymbol{W}^{0.5}$, e definindo: $$\tilde{\boldsymbol{X}} \equiv \boldsymbol{W}^{0.5} \boldsymbol{X} \qquad \text{e} \qquad \tilde{\boldsymbol{y}} \equiv \boldsymbol{W}^{0.5} \boldsymbol{y}$$
-
No exemplo em que a variância da mulher é o dobro da variância do homem, temos: \begin{align} \boldsymbol{W}^{0.5} \boldsymbol{y} &= \begin{bmatrix} 2^{0.5} & \cdots & 0 & 0 & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & 2^{0.5} & 0 & \cdots & 0 \\ 0 & \cdots & 0 & 1^{0.5} & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & 0 & 0 & \cdots & 1^{0.5} \\ \end{bmatrix} \begin{bmatrix} y_1 \\ \vdots \\ y_M \\ y_{M+1} \\ \vdots \\ y_N \end{bmatrix}\\ &= \begin{bmatrix} \frac{1}{\sqrt{2}} & \cdots & 0 & 0 & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & \frac{1}{\sqrt{2}} & 0 & \cdots & 0 \\ 0 & \cdots & 0 & \frac{1}{\sqrt{1}} & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & 0 & 0 & \cdots & \frac{1}{\sqrt{1}} \\ \end{bmatrix} \begin{bmatrix} y_1 \\ \vdots \\ y_M \\ y_{M+1} \\ \vdots \\ y_N \end{bmatrix} \\ &= \begin{bmatrix} \frac{1}{\sqrt{2}} y_1 \\ \vdots \\ \frac{1}{\sqrt{2}} y_M \\ \frac{1}{\sqrt{1}} y_{M+1} \\ \vdots \\ \frac{1}{\sqrt{1}} y_N \end{bmatrix} \end{align} em que $M$ é o número de mulheres na base de dados.
-
Note que as variáveis $\boldsymbol{y}$ e $\boldsymbol{X}$ ficam multiplicadas pelo inverso da raiz de seus respectivos pesos, quando as pré-multiplicamos por $\boldsymbol{W}$.
-
Observe também que os estimadores são equivalentes: \begin{align} \hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQP}} &= \left(\boldsymbol{X}' \boldsymbol{W} \boldsymbol{X} \right)^{-1} \left(\boldsymbol{X}' \boldsymbol{W} \boldsymbol{y} \right) \\ &= \left(\boldsymbol{X}' \boldsymbol{W}^{0.5} \boldsymbol{W}^{0.5} \boldsymbol{X} \right)^{-1} \left(\boldsymbol{X}' \boldsymbol{W}^{0.5} \boldsymbol{W}^{0.5} \boldsymbol{y} \right) \\ &= \left(\boldsymbol{X}' {\boldsymbol{W}^{0.5}}^{\prime} \boldsymbol{W}^{0.5} \boldsymbol{X} \right)^{-1} \left(\boldsymbol{X}' {\boldsymbol{W}^{0.5}}^{\prime} \boldsymbol{W}^{0.5} \boldsymbol{y} \right) \\ &= \left( \left[ \boldsymbol{W}^{0.5} \boldsymbol{X} \right]' \boldsymbol{W}^{0.5} \boldsymbol{X} \right)^{-1} \left(\left[ \boldsymbol{W}^{0.5} \boldsymbol{X} \right]' \boldsymbol{W}^{0.5} \boldsymbol{y} \right) \\ &= ( \tilde{\boldsymbol{X}}' \tilde{\boldsymbol{X}} )^{-1} (\tilde{\boldsymbol{X}}' \tilde{\boldsymbol{y}} ) \equiv \tilde{\hat{\boldsymbol{\beta}}}_{\scriptscriptstyle{MQO}} \end{align} e \begin{align} V(\hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQP}}) &= \sigma^2 \left(\boldsymbol{X}' \boldsymbol{W} \boldsymbol{X} \right)^{-1} \\ &= \sigma^2 \left(\boldsymbol{X}' {\boldsymbol{W}^{0.5}} \boldsymbol{W}^{0.5} \boldsymbol{X} \right)^{-1} \\ &= \sigma^2 \left(\boldsymbol{X}' {\boldsymbol{W}^{0.5}}^{\prime} \boldsymbol{W}^{0.5} \boldsymbol{X} \right)^{-1} \\ &= \sigma^2 \left(\left[ \boldsymbol{W}^{0.5} \boldsymbol{X} \right]' \boldsymbol{W}^{0.5} \boldsymbol{X} \right)^{-1} \\ V(\tilde{\hat{\boldsymbol{\beta}}}_{\scriptscriptstyle{MQO}}) &= \sigma^2 (\tilde{\boldsymbol{X}}' \tilde{\boldsymbol{X}} )^{-1} \end{align}
em que usamos $\boldsymbol{W}^{0.5} = {\boldsymbol{W}^{0.5}}^{\prime}$ (matriz simétrica).
Estimação via lm()
- Aqui usaremos um exemplo parecido com o que simulamos em uma seção anterior, pois é difícil encontrar um exemplo que saiba o formato exato da heterocedasticidade à priori.
- Vamos criar observações do seguinte modelo real com presença de heterocedasticidade: $$ y = \tilde{\beta}_0 + \tilde{\beta}_1 x + \tilde{\varepsilon}, \qquad \tilde{\varepsilon} \sim N(0, (10x)^2) $$ logo $$ Var(\tilde{\varepsilon}_i | x_i) = \sigma^2 (10x_i)^2 \quad \implies\quad sd(\tilde{\varepsilon}_i | x_i) = \sigma (10x_i) $$
- Para estimar o MQP via
lm(), precisamos informar os pesos no argumentoweights
# Definindo parâmetros
b0til = 50
b1til = -5
N = 100
# Gerando x e y por simulação
set.seed(123)
x = runif(N, 1, 9) # Gerando 100 obs. de x
e_til = rnorm(N, 0, 10*x) # Erros: 100 obs. de média 0 e desv pad 10x
y = b0til + b1til*x + e_til # calculando observações y
plot(x, y)
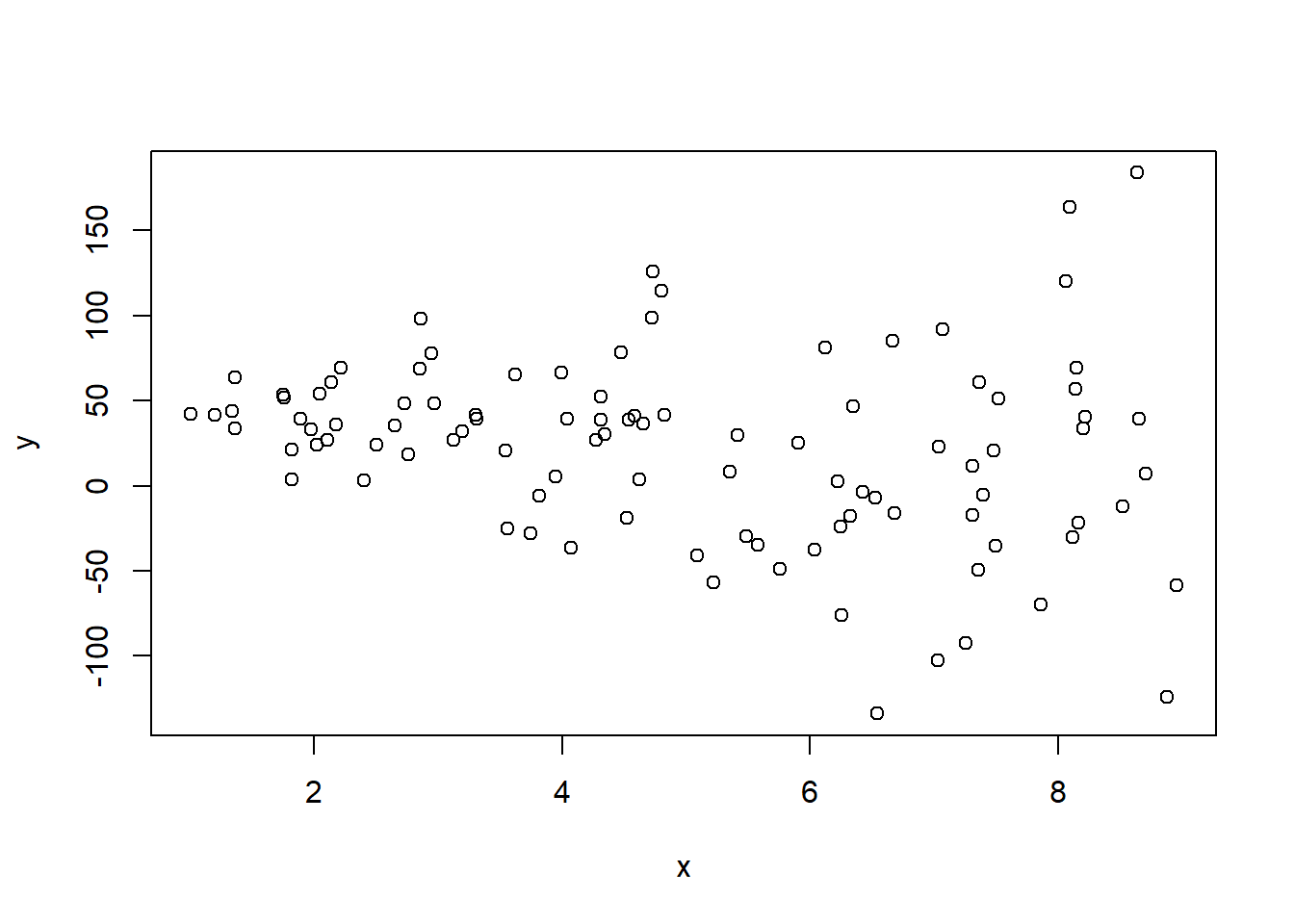
- Agora, vamos estimar por MQO e MQP o seguinte modelo empírico $$ y = \beta_0 + \beta_1 x + \varepsilon $$
# Estimações
reg.ols = lm(y ~ x) # estimação por MQO
reg.wls = lm(y ~ x, weights=1/(10*x)^2) # estimação por MQP
stargazer::stargazer(reg.ols, reg.wls, digits=2, type="text", omit.stat="f")
##
## ==========================================================
## Dependent variable:
## ----------------------------
## y
## (1) (2)
## ----------------------------------------------------------
## x -5.51** -5.92***
## (2.35) (1.77)
##
## Constant 49.27*** 51.43***
## (12.87) (5.50)
##
## ----------------------------------------------------------
## Observations 100 100
## R2 0.05 0.10
## Adjusted R2 0.04 0.09
## Residual Std. Error (df = 98) 53.30 0.97
## ==========================================================
## Note: *p<0.1; **p<0.05; ***p<0.01
- Veja que a estimação por MQP foi mais eficiente - produziu erros padrão menores, dado que já sabíamos que a variância do erro era proporcional à variável x.
- Na prática, é difícil conhecer/defender uma forma exata da heterocedasticidade, já que não conhecemos o modelo real da variância do erro.
- Abaixo, segue uma estimação feita com pesos errados $ Var(\tilde{\varepsilon}_i | x_i) = \sigma^2 \left(\frac{1}{10 x_i}\right)^2$ e note que, inclusive, afeta a estimativas (além de piorar os erros padrão):
# Estimações
reg.wls2 = lm(y ~ x, weights=x^2) # estimação por MQP
stargazer::stargazer(reg.ols, reg.wls, reg.wls2, digits=2, type="text", omit.stat="f")
##
## ===========================================================
## Dependent variable:
## -----------------------------
## y
## (1) (2) (3)
## -----------------------------------------------------------
## x -5.51** -5.92*** -2.60
## (2.35) (1.77) (3.88)
##
## Constant 49.27*** 51.43*** 30.54
## (12.87) (5.50) (26.90)
##
## -----------------------------------------------------------
## Observations 100 100 100
## R2 0.05 0.10 0.005
## Adjusted R2 0.04 0.09 -0.01
## Residual Std. Error (df = 98) 53.30 0.97 368.51
## ===========================================================
## Note: *p<0.1; **p<0.05; ***p<0.01
Estimação Analítica
a) Criando vetores/matrizes e definindo N e K
# Criando o vetor y
y = as.matrix(y) # transformando coluna de data frame em matriz
# Criando a matriz de covariadas X com primeira coluna de 1's
X = as.matrix( cbind(1, x) ) # juntando 1's com x
# Pegando valores N e K
N = nrow(X)
K = ncol(X) - 1
b) Matriz de pesos $\boldsymbol{W}$
- É a matriz cuja diagonal principal é preenchida pelos pesos, $w_i = 1/x^2_i$
W = diag(1/x^2)
round(W[1:10,1:10], 2)
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
## [1,] 0.09 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
## [2,] 0.00 0.02 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
## [3,] 0.00 0.00 0.05 0.00 0.00 0.00 0.00 0.00 0.00 0.00
## [4,] 0.00 0.00 0.00 0.02 0.00 0.00 0.00 0.00 0.00 0.00
## [5,] 0.00 0.00 0.00 0.00 0.01 0.00 0.00 0.00 0.00 0.00
## [6,] 0.00 0.00 0.00 0.00 0.00 0.54 0.00 0.00 0.00 0.00
## [7,] 0.00 0.00 0.00 0.00 0.00 0.00 0.04 0.00 0.00 0.00
## [8,] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.02 0.00 0.00
## [9,] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.03 0.00
## [10,] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.05
c) Estimativas MQP $\hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQP}}$
$$ \hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQP}} = (\boldsymbol{X}' \boldsymbol{W} \boldsymbol{X})^{-1} \boldsymbol{X}' \boldsymbol{W} \boldsymbol{y} $$bhat_wls = solve( t(X) %*% W %*% X ) %*% t(X) %*% W %*% y
bhat_wls
## [,1]
## 51.433290
## x -5.923353
d) Valores ajustados $\hat{\boldsymbol{y}}_{\scriptscriptstyle{MQP}}$
yhat_wls = X %*% bhat_wls
head(yhat_wls)
## [,1]
## [1,] 31.8825514
## [2,] 8.1546597
## [3,] 26.1298192
## [4,] 3.6665460
## [5,] 0.9441786
## [6,] 43.3511590
e) Resíduos $\hat{\boldsymbol{\varepsilon}}_{\scriptscriptstyle{MQP}}$
ehat_wls = y - yhat_wls
head(ehat_wls)
## [,1]
## [1,] 9.9754298
## [2,] 3.2273830
## [3,] 0.6797571
## [4,] 116.3787515
## [5,] -12.8069979
## [6,] 20.5180944
f) Estimativa da variância do erro $\hat{\sigma}^2_{\scriptscriptstyle{MQP}}$ $$\hat{\sigma}^2 = \frac{\hat{\boldsymbol{\varepsilon}}' \boldsymbol{W} \hat{\boldsymbol{\varepsilon}}}{N - K - 1} $$
sig2hat_wls = as.numeric( t(ehat_wls) %*% W %*% ehat_wls / (N-K-1) )
sig2hat_wls
## [1] 93.95364
h) Matriz de Variâncias-Covariâncias do Estimador
$$ \widehat{\text{Var}}(\hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQP}}) = \hat{\sigma}^2 (\boldsymbol{X}' \boldsymbol{W} \boldsymbol{X})^{-1} $$Vbhat_wls = sig2hat_wls * solve( t(X) %*% W %*% X )
round(Vbhat_wls, 3)
## x
## 30.248 -8.144
## x -8.144 3.132
i) Erros-padrão, estatísticas t e p-valores
se_wls = sqrt( diag(Vbhat_wls) )
t_wls = bhat_wls / se_wls
p_wls = 2 * pt(-abs(t_wls), N-K-1)
# Resultados
data.frame(bhat_wls, se_wls, t_wls, p_wls) # resultado MQP
## bhat_wls se_wls t_wls p_wls
## 51.433290 5.499861 9.351743 3.090884e-15
## x -5.923353 1.769796 -3.346913 1.159943e-03
summary(reg.wls)$coef # resultado MQP via lm()
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 51.433290 5.499861 9.351743 3.090884e-15
## x -5.923353 1.769796 -3.346913 1.159943e-03
Transformando e estimando por MQO
- Agora, vamos transformar as variáveis e resolver por MQO, pré-multiplicando $\boldsymbol{X}$ e $\boldsymbol{y}$ por $ \boldsymbol{W}^{0.5}$, e definindo:
b’) Matriz de pesos $\boldsymbol{W}^{0.5}$
- É a matriz cuja diagonal principal é preenchida pelas raízes quadradas dos pesos
W_0.5 = diag(1/(10*x))
round(W_0.5[1:10,1:10], 2)
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
## [1,] 0.03 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
## [2,] 0.00 0.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
## [3,] 0.00 0.00 0.02 0.00 0.00 0.00 0.00 0.00 0.00 0.00
## [4,] 0.00 0.00 0.00 0.01 0.00 0.00 0.00 0.00 0.00 0.00
## [5,] 0.00 0.00 0.00 0.00 0.01 0.00 0.00 0.00 0.00 0.00
## [6,] 0.00 0.00 0.00 0.00 0.00 0.07 0.00 0.00 0.00 0.00
## [7,] 0.00 0.00 0.00 0.00 0.00 0.00 0.02 0.00 0.00 0.00
## [8,] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.00 0.00
## [9,] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.02 0.00
## [10,] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.02
b’’) Variáveis transformadas $\tilde{\boldsymbol{y}}$ e $\tilde{\boldsymbol{X}}$
ytil = W_0.5 %*% y
Xtil = W_0.5 %*% X
# Gráficos
plot(x, ytil, ylim=c(-125,175),
main=expression(paste("Gráfico ", x ," \u00D7 ", tilde(y))),
xlab=expression(x), ylab=expression(tilde(y))) # plot xtil e ytil

plot(x, y, ylim=c(-125,175),
main=expression(paste("Gráfico ", x ," \u00D7 ", y)),
xlab=expression(x), ylab=expression(y)) # plot x e y

c’) Estimativas MQO $\tilde{\hat{\boldsymbol{\beta}}}_{\scriptscriptstyle{MQO}}$
$$ \tilde{\hat{\boldsymbol{\beta}}}_{\scriptscriptstyle{MQo}} = (\tilde{\boldsymbol{X}}' \tilde{\boldsymbol{X}})^{-1} \tilde{\boldsymbol{X}}' \tilde{\boldsymbol{y}} $$bhat_ols = solve( t(Xtil) %*% Xtil ) %*% t(Xtil) %*% ytil
bhat_ols
## [,1]
## 51.433290
## x -5.923353
d’) Valores ajustados $\tilde{\hat{\boldsymbol{y}}}_{\scriptscriptstyle{MQO}}$
yhat_ols = Xtil %*% bhat_ols
head(yhat_ols)
## [,1]
## [1,] 0.96595639
## [2,] 0.11160919
## [3,] 0.61167951
## [4,] 0.04546730
## [5,] 0.01107705
## [6,] 3.17718463
e’) Resíduos $\tilde{\hat{\boldsymbol{\varepsilon}}}_{\scriptscriptstyle{MQO}}$
ehat_ols = ytil - yhat_ols
head(ehat_ols)
## [,1]
## [1,] 0.30222895
## [2,] 0.04417175
## [3,] 0.01591261
## [4,] 1.44316397
## [5,] -0.15025095
## [6,] 1.50376081
f’) Estimativa da variância do erro $\tilde{\hat{\sigma}}^2_{\scriptscriptstyle{MQO}}$ $$\tilde{\hat{\sigma}}^2 = \frac{\tilde{\hat{\boldsymbol{\varepsilon}}}' \tilde{\hat{\boldsymbol{\varepsilon}}}}{N - K - 1} $$
sig2hat_ols = as.numeric( t(ehat_ols) %*% ehat_ols / (N-K-1) )
sig2hat_ols
## [1] 0.9395364
h’) Matriz de Variâncias-Covariâncias do Estimador
$$ \widehat{\text{Var}}(\hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQO}}) = \tilde{\hat{\sigma}}^2(\tilde{\boldsymbol{X}}' \tilde{\boldsymbol{X}})^{-1} $$Vbhat_ols = sig2hat_ols * solve( t(Xtil) %*% Xtil )
round(Vbhat_ols, 3)
## x
## 30.248 -8.144
## x -8.144 3.132
i’) Erros-padrão, estatísticas t e p-valores
se_ols = sqrt( diag(Vbhat_ols) )
t_ols = bhat_ols / se_ols
p_ols = 2 * pt(-abs(t_ols), N-K-1)
# Resultados
data.frame(bhat_ols, se_ols, t_ols, p_ols) # resultado MQO transformado
## bhat_ols se_ols t_ols p_ols
## 51.433290 5.499861 9.351743 3.090884e-15
## x -5.923353 1.769796 -3.346913 1.159943e-03
summary(reg.wls)$coef # resultado MQP via lm()
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 51.433290 5.499861 9.351743 3.090884e-15
## x -5.923353 1.769796 -3.346913 1.159943e-03
Estimador MQGF
-
Na prática, é difícil conhecer a priori a matriz de variâncias-covariâncias dos erros.
-
Uma forma razoável é supor que $\boldsymbol{\Sigma}$ é uma função de parâmetros de um modelo linear $\boldsymbol{\gamma}$ desconhecidos.
-
Assim, podemos calcular $\hat{\boldsymbol{\gamma}}$ para obter $\boldsymbol{\Sigma}(\hat{\boldsymbol{\gamma}})$, a partir de resíduos de MQO.
-
Esse tipo de procedimento é conhecido como Mínimos Quadrados Generalizados Factíveis (MQGF/FGLS), pois seu cálculo é possível enquanto o MQG não é.
-
Note que, se $\boldsymbol{\Sigma}(\hat{\boldsymbol{\gamma}})$ não for uma boa aproximação de $\boldsymbol{\Sigma}$, então as estimativas e inferências por MQGF poderão ser ruins.
-
Queremos estimar o modelo $$y_i = \beta_0 + \beta_1 x_{i1} + ... + \beta_K x_{iK} + \varepsilon_i = \boldsymbol{x}'_i \boldsymbol{\beta} + \varepsilon_i, \tag{1} $$ enquanto, geralmente, assume-se a variância do erro individual é dada por: $$Var(\varepsilon_i | \boldsymbol{x}'_i) = \sigma^2 \exp(\boldsymbol{x}'_i \boldsymbol{\gamma}). $$
-
A função $\exp(\boldsymbol{x}'_i \boldsymbol{\gamma})$ é um exemplo de função skedastic, que garante que, após cálculo de $\hat{\boldsymbol{\gamma}}$, o valor ajustado não seja negativo (para a variância do indivíduo ser sempre positiva).
-
Para estimar $\boldsymbol{\gamma}$, é necessário ter estimativas $\hat{\boldsymbol{\varepsilon}}$ consistentes. A forma mais comum é começar calculando $\hat{\boldsymbol{\varepsilon}}_{\scriptscriptstyle{MQO}}$.
-
Depois, é feita a regressão linear auxiliar $$ \log{\hat{\varepsilon}}^2_i = \boldsymbol{x}'_i \boldsymbol{\gamma} + u_i, \tag{2} $$
-
A partir da estimação, podemos usar os valores ajustados para calcular $$h(\boldsymbol{x}'_i) = \exp(\boldsymbol{x}'_i \boldsymbol{\gamma})$$ que é a inverso do peso $$w_i = \frac{1}{h(\boldsymbol{x}'_i)} = \frac{1}{\exp(\boldsymbol{x}'_i \boldsymbol{\gamma})}$$
-
Com $\boldsymbol{W}$ estimado, podemos calcular $\hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQGF}}$ e $V(\hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQGF}})$, seguindo os mesmos passos de MQP.
-
Podemos usar esse $\hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQGF}}$ estimado para estimar um novo $\boldsymbol{\gamma}$ e um novo $\hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQGF}}$. Isso pode ser feito iteradamente até sua convergência (se isso ocorrer) ou até um certo número de repetições.
Estimação via lm()
data(smoke, package="wooldridge")
# Estimação por MQO
reg.ols = lm(cigs ~ lincome + lcigpric + educ + age + agesq + restaurn,
data=smoke)
round(summary(reg.ols)$coef, 4)
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -3.6398 24.0787 -0.1512 0.8799
## lincome 0.8803 0.7278 1.2095 0.2268
## lcigpric -0.7509 5.7733 -0.1301 0.8966
## educ -0.5015 0.1671 -3.0016 0.0028
## age 0.7707 0.1601 4.8132 0.0000
## agesq -0.0090 0.0017 -5.1765 0.0000
## restaurn -2.8251 1.1118 -2.5410 0.0112
# Obtenção dos pesos wi = 1/h(zi) = 1/exp(Xg)
logu2 = log(resid(reg.ols)^2)
reg.var = lm(logu2 ~ lincome + lcigpric + educ + age + agesq + restaurn,
data=smoke)
w = 1/exp(fitted(reg.var))
# Estimação por MQGF
reg.fgls = lm(cigs ~ lincome + lcigpric + educ + age + agesq + restaurn,
weight=w, data=smoke)
round(summary(reg.fgls)$coef, 4)
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 5.6355 17.8031 0.3165 0.7517
## lincome 1.2952 0.4370 2.9639 0.0031
## lcigpric -2.9403 4.4601 -0.6592 0.5099
## educ -0.4634 0.1202 -3.8570 0.0001
## age 0.4819 0.0968 4.9784 0.0000
## agesq -0.0056 0.0009 -5.9897 0.0000
## restaurn -3.4611 0.7955 -4.3508 0.0000
Estimação Analítica
- Parecida com MQP, apenas o início é diferente: a) Criando vetores/matrizes e definindo N e K
# Criando o vetor y
y = as.matrix(smoke[,"cigs"]) # transformando coluna de data frame em matriz
# Criando a matriz de covariadas X com primeira coluna de 1's
X = as.matrix( cbind(1, smoke[,c("lincome", "lcigpric", "educ", "age", "agesq",
"restaurn")]) ) # juntando 1's com x
# Pegando valores N e K
N = nrow(X)
K = ncol(X) - 1
b1) Estimação por MQO para obter $\hat{\boldsymbol{\varepsilon}}_{\scriptscriptstyle{MQO}}$
bhat_ols = solve(t(X) %*% X) %*% t(X) %*% y
yhat = X %*% bhat_ols
ehat = y - yhat
b2) Regressão do log dos resíduos ao quadrado e estimação de $\hat{\boldsymbol{\gamma}}$ $$ \log{\hat{\boldsymbol{\varepsilon}}}^2 = \boldsymbol{X} \boldsymbol{\gamma} + \boldsymbol{u} $$
ghat = solve( t(X) %*% X ) %*% t(X) %*% log(ehat^2)
b3) Matriz de pesos $\boldsymbol{W}$ $$\boldsymbol{W} = diag\left(\frac{1}{\exp(\boldsymbol{X} \hat{\boldsymbol{\gamma}})}\right) = \begin{bmatrix} \frac{1}{\exp(\boldsymbol{x}'_1\hat{\boldsymbol{\gamma}})} & 0 & \cdots & 0 \\ 0 & \frac{1}{\exp(\boldsymbol{x}'_2\hat{\boldsymbol{\gamma}})} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \frac{1}{\exp(\boldsymbol{x}'_N\hat{\boldsymbol{\gamma}})} \end{bmatrix}$$
W = diag(as.numeric(1 / exp(X %*% ghat)))
round(W[1:7,1:7], 3)
## [,1] [,2] [,3] [,4] [,5] [,6] [,7]
## [1,] 0.008 0.000 0.000 0.00 0.000 0.000 0.000
## [2,] 0.000 0.007 0.000 0.00 0.000 0.000 0.000
## [3,] 0.000 0.000 0.009 0.00 0.000 0.000 0.000
## [4,] 0.000 0.000 0.000 0.01 0.000 0.000 0.000
## [5,] 0.000 0.000 0.000 0.00 0.024 0.000 0.000
## [6,] 0.000 0.000 0.000 0.00 0.000 0.444 0.000
## [7,] 0.000 0.000 0.000 0.00 0.000 0.000 0.007
- Os próximos passos são os mesmos de MQP:
c) Estimativas MQGF $\hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQGF}}$ $$ \hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQGF}} = (\boldsymbol{X}' \boldsymbol{W} \boldsymbol{X})^{-1} \boldsymbol{X}' \boldsymbol{W} \boldsymbol{y} $$
bhat_fgls = solve( t(X) %*% W %*% X ) %*% t(X) %*% W %*% y
bhat_fgls
## [,1]
## 1 5.63546183
## lincome 1.29523990
## lcigpric -2.94031229
## educ -0.46344637
## age 0.48194788
## agesq -0.00562721
## restaurn -3.46106414
d) Valores ajustados $\hat{\boldsymbol{y}}_{\scriptscriptstyle{MQGF}}$
yhat_fgls = X %*% bhat_fgls
head(yhat_fgls)
## [,1]
## 1 9.246793
## 2 9.914233
## 3 10.527827
## 4 9.667243
## 5 8.440092
## 6 2.048962
e) Resíduos $\hat{\boldsymbol{\varepsilon}}_{\scriptscriptstyle{MQGF}}$
ehat_fgls = y - yhat_fgls
head(ehat_fgls)
## [,1]
## 1 -9.246793
## 2 -9.914233
## 3 -7.527827
## 4 -9.667243
## 5 -8.440092
## 6 -2.048962
f) Estimativa da variância do erro $\hat{\sigma}^2_{\scriptscriptstyle{MQGF}}$ $$\hat{\sigma}^2 = \frac{\hat{\boldsymbol{\varepsilon}}' \boldsymbol{W} \hat{\boldsymbol{\varepsilon}}}{N - K - 1} $$
sig2hat_fgls = as.numeric( t(ehat_fgls) %*% W %*% ehat_fgls / (N-K-1) )
sig2hat_fgls
## [1] 2.492289
h) Matriz de Variâncias-Covariâncias do Estimador
$$ \widehat{\text{Var}}(\hat{\boldsymbol{\beta}}_{\scriptscriptstyle{MQP}}) = (\boldsymbol{X}' \boldsymbol{W} \boldsymbol{X})^{-1} $$Vbhat_fgls = sig2hat_fgls * solve( t(X) %*% W %*% X )
round(Vbhat_fgls, 3)
## 1 lincome lcigpric educ age agesq restaurn
## 1 316.952 0.444 -77.432 0.196 -0.389 0.004 2.323
## lincome 0.444 0.191 -0.463 -0.016 -0.007 0.000 0.008
## lcigpric -77.432 -0.463 19.893 -0.050 0.071 -0.001 -0.620
## educ 0.196 -0.016 -0.050 0.014 -0.001 0.000 0.002
## age -0.389 -0.007 0.071 -0.001 0.009 0.000 -0.009
## agesq 0.004 0.000 -0.001 0.000 0.000 0.000 0.000
## restaurn 2.323 0.008 -0.620 0.002 -0.009 0.000 0.633
i) Erros-padrão, estatísticas t e p-valores
se_fgls = sqrt( diag(Vbhat_fgls) )
t_fgls = bhat_fgls / se_fgls
p_fgls = 2 * pt(-abs(t_fgls), N-K-1)
# Resultados
round(data.frame(bhat_fgls, se_fgls, t_fgls, p_fgls), 4) # resultado MQP
## bhat_fgls se_fgls t_fgls p_fgls
## 1 5.6355 17.8031 0.3165 0.7517
## lincome 1.2952 0.4370 2.9639 0.0031
## lcigpric -2.9403 4.4601 -0.6592 0.5099
## educ -0.4634 0.1202 -3.8570 0.0001
## age 0.4819 0.0968 4.9784 0.0000
## agesq -0.0056 0.0009 -5.9897 0.0000
## restaurn -3.4611 0.7955 -4.3508 0.0000
round(summary(reg.fgls)$coef, 4) # resultado MQGF via lm()
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 5.6355 17.8031 0.3165 0.7517
## lincome 1.2952 0.4370 2.9639 0.0031
## lcigpric -2.9403 4.4601 -0.6592 0.5099
## educ -0.4634 0.1202 -3.8570 0.0001
## age 0.4819 0.0968 4.9784 0.0000
## agesq -0.0056 0.0009 -5.9897 0.0000
## restaurn -3.4611 0.7955 -4.3508 0.0000