Regressão simples por MQO
- Seção 2.1 de Heiss (2020)
- Considere o seguinte modelo empírico $$ y = \beta_0 + \beta_1 x + u \tag{2.1} $$
- Os estimadores de mínimos quadrados ordinários (MQO), segundo Wooldridge (2006, Seção 2.2) é dado por
- E os valores ajustados/preditos, $\hat{y}$ é dado por $$ \hat{y} = \hat{\beta}_0 + \hat{\beta}_1 x \tag{2.4} $$ tal que $$ y = \hat{y} + \hat{u} $$
Exemplo 2.3: Salário de Diretores Executivos e Retornos de Ações (Wooldridge, 2006)
- Considere o seguinte modelo de regressão simples
$$ \text{salary} = \beta_0 + \beta_1 \text{roe} + u $$
em que
salaryé a remuneração de um diretor executivo em milhares de dólares eroeé o retorno sobre o investimento em percentual.
Estimando regressão simples “na mão”
# Carregando a base de dados do pacote 'wooldridge'
data(ceosal1, package="wooldridge")
attach(ceosal1) # para não precisar escrever 'ceosal1$' antes de toda variável
cov(salary, roe) # covariância entre variável dependente e independente
## [1] 1342.538
var(roe) # variância do retorno sobre o investimento
## [1] 72.56499
mean(roe) # média do retorno sobre o investimento
## [1] 17.18421
mean(salary) # média do salário
## [1] 1281.12
# Cálculo "na mão" dos coeficientes de MQO
( b1_hat = cov(salary, roe) / var(roe) ) # por (2.3)
## [1] 18.50119
( b0_hat = mean(salary) - var(roe)*mean(salary) ) # por (2.2)
## [1] -91683.31
detach(ceosal1) # para parar de procurar variável dentro do objeto 'ceosal1'
- Vemos que um incremento de uma unidade (porcento) no retorno sobre o investimento (roe), aumentar 18 unidades (milhares de dólares) nos salários dos diretores executivos.
Estimando regressão simples via lm()
- Uma maneira mais conveniente de fazer a estimação por MQO é usando a função
lm() - Em um modelo univariado, inserimos dois vetores (variáveis dependente e independente) separados por um til (
~):
lm(ceosal1$salary ~ ceosal1$roe)
##
## Call:
## lm(formula = ceosal1$salary ~ ceosal1$roe)
##
## Coefficients:
## (Intercept) ceosal1$roe
## 963.2 18.5
- Também podemos deixar de usar o prefixo
ceosal1$antes dos nomes do vetores preenchermos o argumentodata = ceosal1
lm(salary ~ roe, data=ceosal1)
##
## Call:
## lm(formula = salary ~ roe, data = ceosal1)
##
## Coefficients:
## (Intercept) roe
## 963.2 18.5
- Podemos usar a função
lm()para incluir uma reta de regressão no gráfico
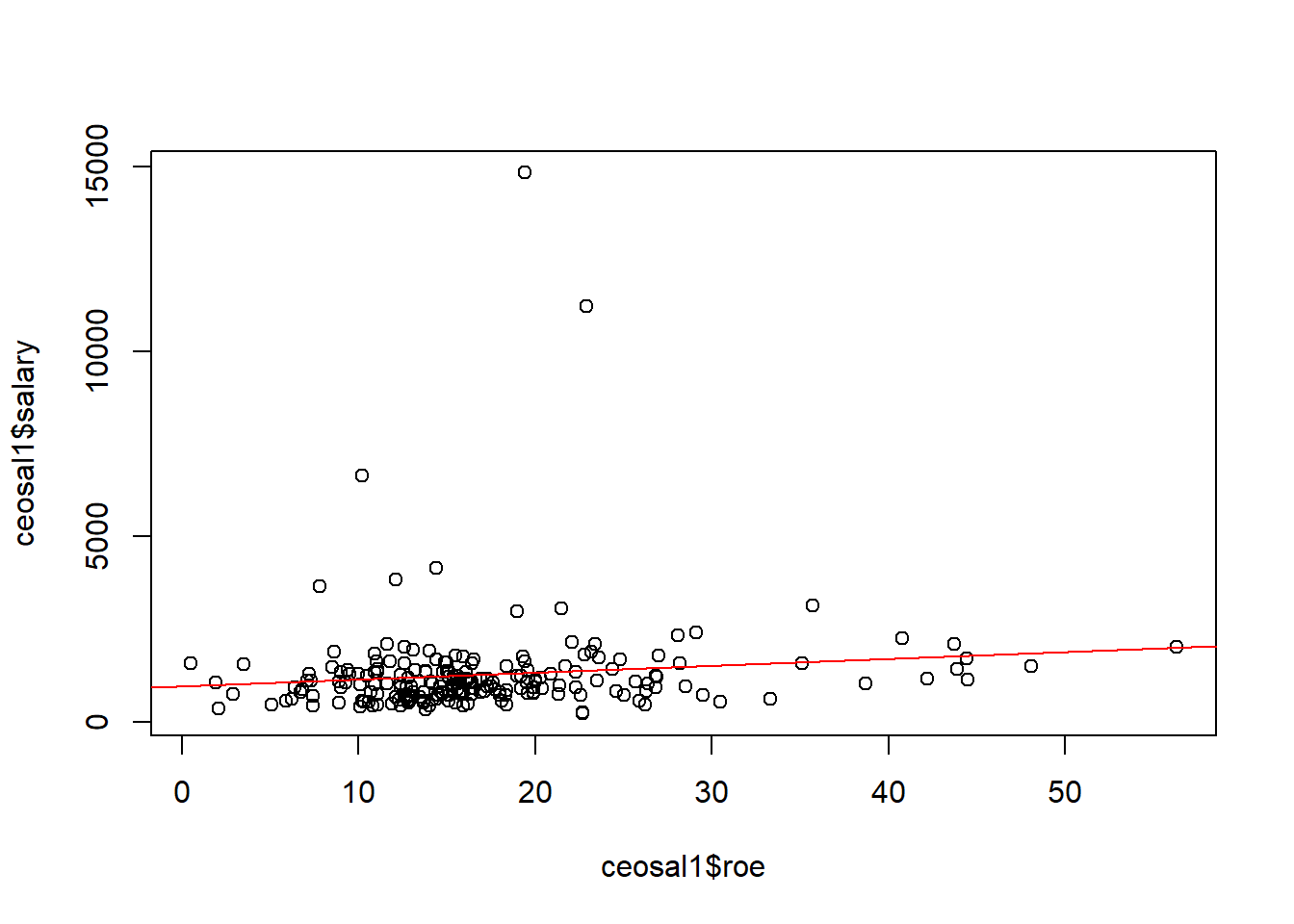
# Gráfico de dispersão (scatter)
plot(ceosal1$roe, ceosal1$salary)
# Adicionando a reta de regressão
abline(lm(salary ~ roe, data=ceosal1), col="red")
Coeficientes, Valores Ajustados e Resíduos
- Seção 2.2 de Heiss (2020)
- Podemos “guardar” os resultados da estimação em um objeto (da classe
list) e, depois, extrair informações dele.
# atribuindo o resultado da regressão em um objeto
CEOregres = lm(salary ~ roe, data=ceosal1)
# verificando os "nomes" das informações contidas no objeto
names(CEOregres)
## [1] "coefficients" "residuals" "effects" "rank"
## [5] "fitted.values" "assign" "qr" "df.residual"
## [9] "xlevels" "call" "terms" "model"
- Podemos usar a função
coef()para extrairmos um data frame com os coeficientes da regressão
( bhat = coef(CEOregres) )
## (Intercept) roe
## 963.19134 18.50119
bhat_0 = bhat["(Intercept)"] # ou bhat[1]
bhat_1 = bhat["roe"] # ou bhat[2]
- Dados estes parâmetros estimados, podemos calcular os valores ajustados/preditos, $\hat{y}$, e os desvios, $\hat{u}$, para cada observação $i=1, ..., n$:
# Extraindo colunas de ceosal1 em vetores
sal = ceosal1$salary
roe = ceosal1$roe
# Calculando os valores ajustados/preditos
sal_hat = bhat_0 + (bhat_1 * roe)
# Calculando os desvios
u_hat = sal - sal_hat
# Visualizando as 6 primerias linhas de sal, roe, sal_hat e u_hat
head( cbind(sal, roe, sal_hat, u_hat) )
## sal roe sal_hat u_hat
## [1,] 1095 14.1 1224.058 -129.0581
## [2,] 1001 10.9 1164.854 -163.8543
## [3,] 1122 23.5 1397.969 -275.9692
## [4,] 578 5.9 1072.348 -494.3483
## [5,] 1368 13.8 1218.508 149.4923
## [6,] 1145 20.0 1333.215 -188.2151
- Com as funções
fitted()eresid()podemos extrair os valores ajustados e os resíduos do objeto com resultado da regressão:
head( cbind(fitted(CEOregres), resid(CEOregres)) )
## [,1] [,2]
## 1 1224.058 -129.0581
## 2 1164.854 -163.8543
## 3 1397.969 -275.9692
## 4 1072.348 -494.3483
## 5 1218.508 149.4923
## 6 1333.215 -188.2151
# Ou também
head( cbind(CEOregres$fitted.values, CEOregres$residuals) )
## [,1] [,2]
## 1 1224.058 -129.0581
## 2 1164.854 -163.8543
## 3 1397.969 -275.9692
## 4 1072.348 -494.3483
## 5 1218.508 149.4923
## 6 1333.215 -188.2151
-
Na seção 2.3 de Wooldridge (2006), vemos que a estimação por MQO assume as seguintes hipóteses: \begin{align} &\sum^n_{i=1}{\hat{u}_i} = 0 \quad \implies \quad \bar{\hat{u}} = 0 \tag{2.7} \\ &\sum^n_{i=1}{x_i \hat{u}_i} = 0 \quad \implies \quad Cov(x,\hat{u}) = 0 \tag{2.8} \\ &\bar{y}=\hat{\beta}_0 + \hat{\beta}_1.\bar{x} \tag{2.9} \end{align}
-
Podemos verificá-los em nosso exemplo:
# Verificando (2.7)
mean(u_hat) # bem próximo de 0
## [1] -2.666235e-14
# Verificando (2.8)
cor(ceosal1$roe, u_hat) # bem próximo de 0
## [1] -6.038735e-17
# Verificando (2.9)
mean(ceosal1$salary)
## [1] 1281.12
mean(sal_hat)
## [1] 1281.12
- IMPORTANTE: Isso só quer dizer que o MQO escolhe $\hat{\beta}_0$ e $\hat{\beta}_1$ tais que 2.7, 2.8 e 2.9 sejam verdadeiros.
- Isto NÃO quer dizer que, para o modelo empírico/populacional, as seguintes hipóteses sejam verdadeiras: \begin{align} &E(u) = 0 \tag{2.7'} \\ &Cov(x, u) = 0 \tag{2.8'} \end{align}
- De fato, se 2.7’ e 2.8’ não forem válidos, a estimação por MQO (que assume 2.7, 2.8 e 2.9) será viesada.
Transformações log
- Seção 2.4 de Heiss (2020)
- Também podemos fazer estimações transformando variáveis em nível para logaritmo.
- É especialmente importante para transformar modelos não-lineares em lineares - quando o parâmetro está no expoente ao invés estar multiplicando:
$$ y = A K^\alpha L^\beta\quad \overset{\text{log}}{\rightarrow}\quad \log(y) = \log(A) + \alpha \log(K) + \beta \log(L) $$
- Também é frequentemente utilizada em variáveis dependentes $y \ge 0$

- Há duas maneiras de fazer a transformação log:
- Criar um novo vetor/coluna com a variável em log, ou
- Usar a função
log()diretamente no vetor dentro da funçãolm()
Exemplo 2.11: Salário de Diretores Executivos e Vendas das Empresas (Wooldridge, 2006)
-
Considere as variáveis:
wage: salário anual em milhares de dólaressales: vendas em milhões de dólares
-
Modelo nível-nível:
# Carregando a base de dados
data(ceosal1, package="wooldridge")
# Estimando modelo nível-nível
lm(salary ~ sales, data=ceosal1)
##
## Call:
## lm(formula = salary ~ sales, data = ceosal1)
##
## Coefficients:
## (Intercept) sales
## 1.174e+03 1.547e-02
- Um aumento em US$ 1 milhão em vendas está relacionado incremento de US$ 0,01547 milhares de dólares do salário do diretor executivo.
- Modelo log-nível:
# Estimando modelo log-nível
lm(log(salary) ~ sales, data=ceosal1)
##
## Call:
## lm(formula = log(salary) ~ sales, data = ceosal1)
##
## Coefficients:
## (Intercept) sales
## 6.847e+00 1.498e-05
- Um aumento em US$ 1 milhão em vendas tende a elevar em 0,0015% ($=100 \beta_1%$ ) o salário do diretor executivo.
- Modelo log-log:
# Estimando modelo log-log
lm(log(salary) ~ log(sales), data=ceosal1)
##
## Call:
## lm(formula = log(salary) ~ log(sales), data = ceosal1)
##
## Coefficients:
## (Intercept) log(sales)
## 4.8220 0.2567
- Um aumento em 1% das vendas aumenta o salário em cerca de 0,257% ($=\beta_1%$) maior.
Regressão a partir da origem e sobre uma constante
- Seção 2.5 de Heiss (2020)
- Para esstimar o modelo sem o intercepto (constante), precisamos adicionar
0 +nos regressores na funçãolm():
data(ceosal1, package="wooldridge")
lm(salary ~ 0 + roe, data=ceosal1)
##
## Call:
## lm(formula = salary ~ 0 + roe, data = ceosal1)
##
## Coefficients:
## roe
## 63.54
- Ao regredirmos uma variável dependente sobre uma constante (1), obtemos a média desta variável.
lm(salary ~ 1, data=ceosal1)
##
## Call:
## lm(formula = salary ~ 1, data = ceosal1)
##
## Coefficients:
## (Intercept)
## 1281
mean(ceosal1$salary, na.rm=TRUE)
## [1] 1281.12
Diferença de médias
- Baseado no Exemplo C.6: Efeito de subsídios de treinamento corporativo sobre a produtividade do trabalhador (Wooldridge, 2006)
- Poderíamos ter calculado a diferença de médias por meio de uma regressão sobre uma variável dummy, cujos valores são 0 ou 1.
- Primeiro vamos criar um vetor único de taxas de refugo (vamos empilhar
SR87eSR88)
SR87 = c(10, 1, 6, .45, 1.25, 1.3, 1.06, 3, 8.18, 1.67, .98,
1, .45, 5.03, 8, 9, 18, .28, 7, 3.97)
SR88 = c(3, 1, 5, .5, 1.54, 1.5, .8, 2, .67, 1.17, .51, .5,
.61, 6.7, 4, 7, 19, .2, 5, 3.83)
( SR = c(SR87, SR88) ) # empilhando SR87 e SR88 em único vetor
## [1] 10.00 1.00 6.00 0.45 1.25 1.30 1.06 3.00 8.18 1.67 0.98 1.00
## [13] 0.45 5.03 8.00 9.00 18.00 0.28 7.00 3.97 3.00 1.00 5.00 0.50
## [25] 1.54 1.50 0.80 2.00 0.67 1.17 0.51 0.50 0.61 6.70 4.00 7.00
## [37] 19.00 0.20 5.00 3.83
- Note que os 20 primeiros valores são relativos às taxas de refugo no ano de 1987 e os 20 últimos valores são de 1988.
- Vamos criar uma variável dummy chamada de group88 que atribui valor 1 as observações do ano de 1988 e o valor 0 para as de 1987:
( group88 = c(rep(0, 20), rep(1, 20)) ) # valores 0/1 para 20 primeiras/últimas observações
## [1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [39] 1 1
- Ao regredirmos a taxa de refugo em relação à dummy obtemos a diferença das médias
lm(SR ~ group88)
##
## Call:
## lm(formula = SR ~ group88)
##
## Coefficients:
## (Intercept) group88
## 4.381 -1.154
Valores esperados, Variância e Erros padrão
-
Wooldridge (2006, Seção 2.5) deriva o estimador do termo de erro: $$ \hat{\sigma}^2 = \frac{1}{n-2} \sum^n_{i=1}{\hat{u}^2_i} = \frac{n-1}{n-2} Var(\hat{u}) \tag{2.14} $$ em que $Var(\hat{u}) = \frac{1}{n-1} \sum^n_{i=1}{\hat{u}^2_i}$.
-
Observe que precisamos considerar os graus de liberdade, dado que estamos estimando dois parâmetros ( $\hat{\beta}_0$ e $\hat{\beta}_1$).
-
Note que $\hat{\sigma} = \sqrt{\hat{\sigma}^2}$ é chamado de erro padrão da regressão (EPR). No R, é chamado de erro padrão residual
-
também podemos obter os erros padrão (EP) dos estimadores:
Exemplo 2.12: Desempenho em Matemática de Estudante e o Programa de Merenda Escolar (Wooldridge, 2006)
-
Sejam as variáveis
math10: o percentual de alunos de primeiro ano de ensino médio aprovados em exame de matemáticalnchprg: o percentual de estudante aptos para participar do programa de merenda escolar
-
O modelo de regressão simples é $$ \text{math10} = \beta_0 + \beta_1 \text{lnchprg} + u $$
data(meap93, package="wooldridge")
# Estimando o modelo e atribuindo no objeto 'results'
results = lm(math10 ~ lnchprg, data=meap93)
# Extraindo número de observações
( n = nobs(results) )
## [1] 408
# Calculando o Erro Padrão da Regressão (raiz quadrada de 2.14)
( SER = sqrt( (n-1)/(n-2) ) * sd(resid(results)) )
## [1] 9.565938
# Erro padrão de bhat_0 (2.15)
(1 / sqrt(n-1)) * (SER / sd(meap93$lnchprg)) * sqrt( mean(meap93$lnchprg^2) ) # Erro padrão de bhat_1 (2.16)
## [1] 0.9975824
(1 / sqrt(n-1)) * (SER / sd(meap93$lnchprg)) # bhat_1
## [1] 0.03483933
- Os cálculos dos erros padrão podem ser obtidos via uso da função
summary()sobre o objeto com resultado da regressão:
summary(results)
##
## Call:
## lm(formula = math10 ~ lnchprg, data = meap93)
##
## Residuals:
## Min 1Q Median 3Q Max
## -24.386 -5.979 -1.207 4.865 45.845
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 32.14271 0.99758 32.221 <2e-16 ***
## lnchprg -0.31886 0.03484 -9.152 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 9.566 on 406 degrees of freedom
## Multiple R-squared: 0.171, Adjusted R-squared: 0.169
## F-statistic: 83.77 on 1 and 406 DF, p-value: < 2.2e-16
- Observe também que, por padrão, são feitos testes de hipótese (bicaudais), cujas hipóteses nulas são $\beta_0 = 0$ e $\beta_1=0$.
- Ou seja, avalia se as estimativas calculadas são estatisticamente nulas e também mostra as respectivas estatísticas t e p-valores.
- Neste caso, como os p-valores são bem pequenos (
<2e-16= menor do que $2 \times 10^{-16}$), rejeitamos ambas hipóteses nulas e, portanto, as estimativas são estatisticamente significantes. - Também podemos calcular essas estimativas “na mão”:
# Extraindo as estimativas
( estim = coef(summary(results)) )
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 32.1427116 0.99758239 32.220609 6.267302e-114
## lnchprg -0.3188643 0.03483933 -9.152422 2.746609e-18
# Estatísticas t para H0: bhat = 0
( t_bhat_0 = (estim["(Intercept)", "Estimate"] - 0) / estim["(Intercept)", "Std. Error"] )
## [1] 32.22061
( t_bhat_1 = (estim["lnchprg", "Estimate"] - 0) / estim["lnchprg", "Std. Error"] )
## [1] -9.152422
# p-valores para H0: bhat = 0
2 * (1 - pt(abs(t_bhat_0), n-1)) # p-valor para bhat_0
## [1] 0
2 * (1 - pt(abs(t_bhat_1), n-1)) # p-valor para bhat_1
## [1] 0
Violações de hipótese
- Subseção 2.7.3 de Heiss (2020), mas usando como exemplo o teste elaborado 1.
- Simulating a linear model (John Hopkins/Coursera)
- Na prática, fazemos regressões a partir de observações contidas em bases de dados e não sabemos qual é o modelo real que gerou essas observações.
- No R, podemos supor um modelo real e simular suas observações no R para analisar o que ocorre quando há violação de hipótese de algum modelo econométrico ou estimador.
- Usaremos o exemplo dado no Teste Elaborado 1, no qual queremos encontrar a relação das horas de prática em culinária com o número de queimaduras na cozinha.
Sem violação de hipótese: Exemplo 1
- Sejam $y$ o número de queimaduras na cozinha e $x$ o número de horas gastas aprendendo a cozinhar.
- Suponha o modelo real: $$ y = a_0 + b_0 x + \varepsilon, \qquad \varepsilon \sim N(0, 2^2) \tag{1}$$ em que $a_0=50$ e $b_0=-5$.
- Definindo
$a_0$ e
$b_0$ e gerando por simulação as “observações” de
$x$ e
$y$:
- Apenas para facilitar, geraremos valores aleatórios $x \sim N(5; 0,5^2)$. Aqui, não importa a distribuição de $x$.
a0 = 50
b0 = -5
N = 200 # Número de observações
set.seed(1)
u = rnorm(N, 0, 2) # Desvios: 200 obs. de média 0 e desv pad 2
x = rnorm(N, 5, 0.5) # Gerando 200 obs. de média 5 e desv pad 1
y = a0 + b0*x + u # calculando observações y a partir de "e" e "x"
plot(x, y)
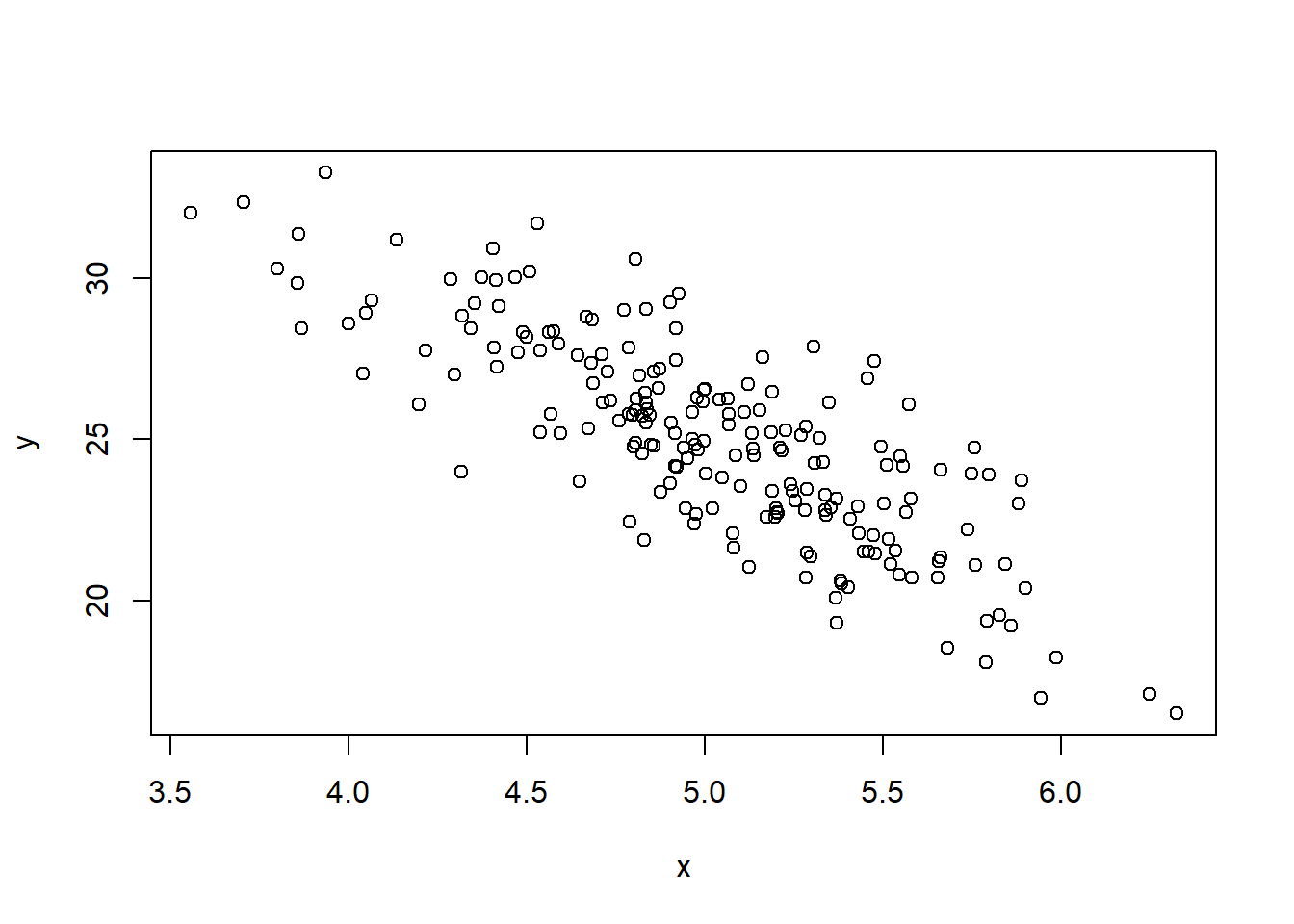 Simulamos as observações
$x$ e
$y$ que são, na prática, as informações que observamos.
Simulamos as observações
$x$ e
$y$ que são, na prática, as informações que observamos.
- Estimando por MQO os parâmetros
$\hat{a}$ e
$\hat{b}$ a partir das observações simuladas de
$y$ e
$x$:
- Um economista supôs a relação entre as variáveis pelo seguinte modelo empírico: $$ y = a + b x + u, \tag{1a}$$ assumindo que $E[u] = 0$ e $E[ux]=0$.
- Para estimar o modelo por MQO, usamos a função
lm()
lm(y ~ x) # regredindo por MQO a var. dependente y pela var. x
##
## Call:
## lm(formula = y ~ x)
##
## Coefficients:
## (Intercept) x
## 50.463 -5.078
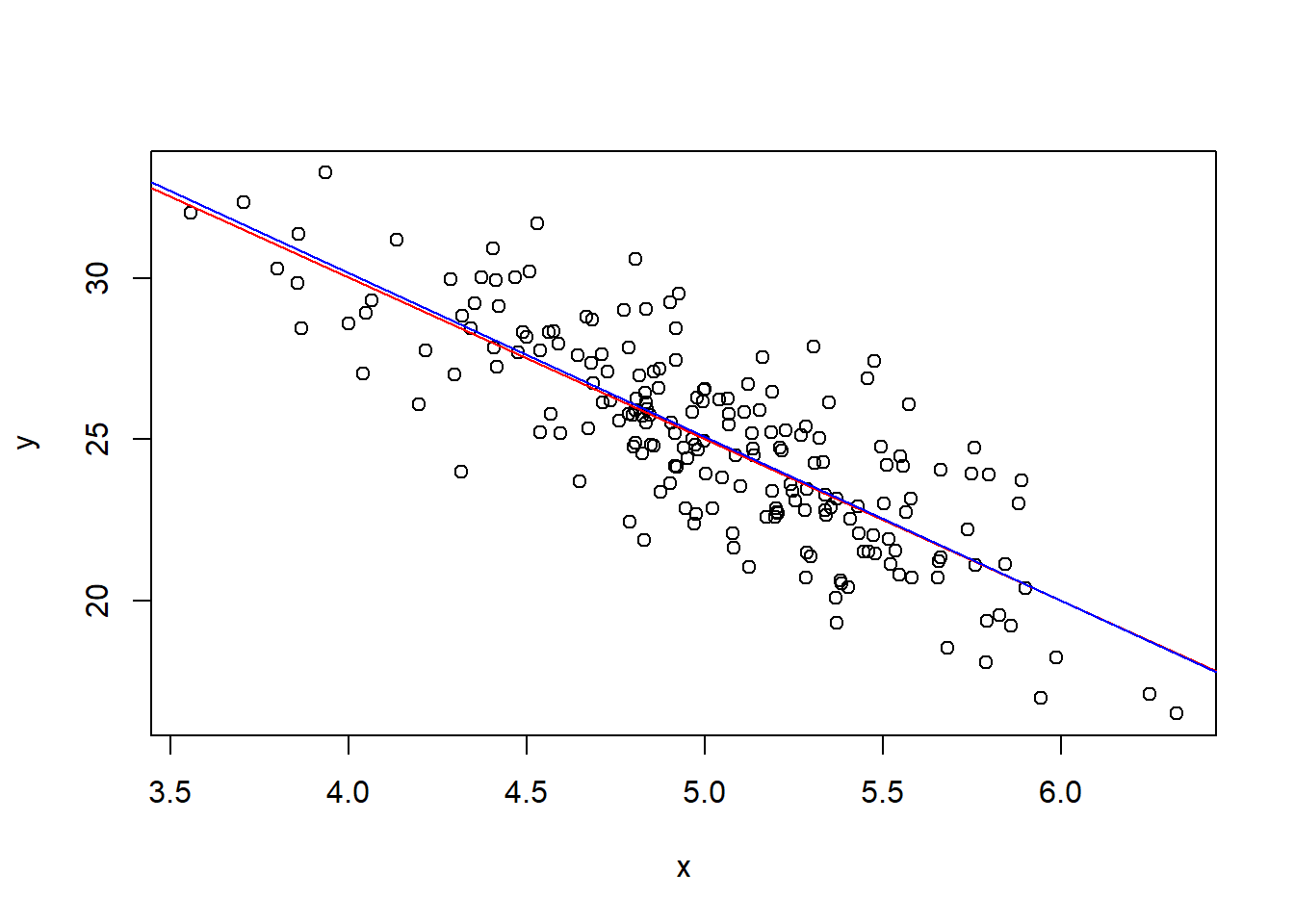
- Note que foi possível recuperar os parâmetros populacionais ( $\hat{a} = 50,268 \approx 50 = a_0$ e $\hat{b} = -5,039 \approx -5 = b_0$).
plot(x, y) # Figura de x contra y
abline(a=50, b=-5, col="red") # reta do modelo real
abline(lm(y ~ x), col="blue") # reta estimada a partir das observações
Sem violação de hipótese: Exemplo 2
- Agora, no modelo real, suponha que o número de queimaduras $y$ é determinado tanto pela quantidade de horas de aprendizado $x$ e pela quantidade de horas gastas cozinhando $z$:
$$ y = a_0 + b_0 x + c_0 z + u, \qquad u \sim N(0, 2^2) \tag{2} $$ em que $a_0=50$, $b_0=-5$ e $c_0=3$. Apenas para facilitar, usaremos geraremos valores aleatórios de $x \sim N(5; 0,5^2)$ e $z \sim N(1,875; 0,25^2)$. Note que $z$, por construção, não é correlacionada com $x$ no modelo real.
- Primeiro, vamos simular as observações:
a0 = 50
b0 = -5
c0 = 3
N = 200 # Número de observações
set.seed(1)
u = rnorm(N, 0, 2) # Desvios: 200 obs. de média 0 e desv pad 2
x = rnorm(N, 5, 0.5) # Gerando 200 obs. de média 5 e desv pad 1
z = rnorm(N, 1.875, 0.25) # Gerando 200 obs. de média 1,875 e desv pad 0.25
y = a0 + b0*x + c0*z + u # calculando observações y a partir de "e", "x" e "z"
-
Considere que um economista suponha a relação entre as variáveis pelo seguinte modelo empírico: $$ y = a + b x + u, \tag{2a}$$ assumindo que $E[u] = 0$ e $E[ux] = 0$.
-
Note que o economista deixou a variável de horas cozinhando $z$ fora do modelo, então ela acaba ``entrando’’ no erro da estimação.
-
No entanto, como $z$ não tem relação com $x$, então isso não afeta a estimativa de $\hat{b}$:
cor(x, z) # correlação de x e z -> próxima de 0
## [1] -0.02625278
lm(y ~ x) # estimação por MQO
##
## Call:
## lm(formula = y ~ x)
##
## Coefficients:
## (Intercept) x
## 56.27 -5.12
- Note que $\hat{b} = -5,12 \approx -5 = b_0$, portanto a estimação por MQO conseguiu recuperar o parâmetro populacional $b_0$, apesar do economista não ter incluído $z$ no modelo.
- Grande parte dos estudos econômicos tentam estabelecer a relação/causalidade entre $y$ e $x$, então não é necessário incluir todas possíveis variáveis que impactam $y$, desde que $E(ux) = 0$ (ou seja, que nenhuma variável explicativa correlacionada com $x$ tenha ``ficado de fora’’ e, portanto, compondo o termo de erro).
Violação de E(ux)=0
- Agora, suponha que, no modelo real, quanto mais horas a pessoa pratica culinária, mais ele cozinha (ou seja,
$x$ está relacionada com
$z$).
- Considere que $z \sim N(1,875x; (0,25)^2)$:
set.seed(1)
e = rnorm(N, 0, 2) # Desvios: 200 obs. de média 0 e desv pad 2
x = rnorm(N, 5, 0.5) # Gerando 200 obs. de média 5 e desv pad 1
z = rnorm(N, 1.875*x, 0.25) # Gerando 200 obs. de média 1,875x e desv pad 0.25x
y = a0 + b0*x + c0*z + e # calculando observações y a partir de "e", "x" e "z"
cor(x, z) # correlação de x e z
## [1] 0.9618748
- Note que, agora, $x$ e $z$ são consideravalmente correlacionados
- Vamos estimar o modelo empírico: $$ y = a + b x + u,$$ assumindo que $E[u] = 0$ e $E[ux]=0$.
lm(y ~ x) # estimação por MQO
##
## Call:
## lm(formula = y ~ x)
##
## Coefficients:
## (Intercept) x
## 50.6406 0.5053
- Observe que $\hat{b} = 0,5 \neq -5 = b_0$. Isto se dá porque $z$ não foi incluído no modelo e, portanto, ele acaba compondo o desvio $\hat{u}$. Como $z$ é correlacionado com $x$, então $E(ux)\neq 0$ (violando a hipótese do MQO).
- Observe que, se incluíssemos a variável $z$ na estimação, conseguiríamos recuperar $\hat{b} \approx b_0$:
lm(y ~ x + z)
##
## Call:
## lm(formula = y ~ x + z)
##
## Coefficients:
## (Intercept) x z
## 50.435 -5.953 3.470
Violação de E(u)=0
- Agora, consideraremos que $E[u] = k$, sendo $k \neq 0$ uma constante.
- Assuma que $k = 10$:
a0 = 50
b0 = -5
k = 10
set.seed(1)
u = rnorm(N, k, 2) # Desvios: 200 obs. de média k e desv pad 2
x = rnorm(N, 5, 0.5) # Gerando 200 obs. de média 5 e desv pad 1
y = a0 + b0*x + u # calculando observações y a partir de "e" e "x"
- Caso um economista considere um modelo empírico com $E[u] = 0$, segue que:
lm(y ~ x) # estimação por MQO
##
## Call:
## lm(formula = y ~ x)
##
## Coefficients:
## (Intercept) x
## 60.463 -5.078
- Note que o fato de $E[u] \neq 0$ afeta apenas a estimação de $\hat{a} \neq a_0$, porém não afeta a de $\hat{b} \approx b_0$, que é normalmente o parâmetro de interesse em estudos econômicos.
Violação de Homocedasticidade
- Agora, consideraremos que $u \sim N(0, (2x)^2)$, ou seja, a variância cresce com $x$ ( $u$ não é independente de $x$/não vale homocedasticidade).
a0 = 50
b0 = -5
set.seed(1)
x = rnorm(N, 5, 0.5) # Gerando 200 obs. de média 5 e desv pad 1
u = rnorm(N, 0, 2*x) # Desvios: 200 obs. de média k e desv pad 2x
y = a0 + b0*x + u # calculando observações y a partir de "e" e "x"
lm(y ~ x) # estimação por MQO
##
## Call:
## lm(formula = y ~ x)
##
## Coefficients:
## (Intercept) x
## 51.221 -5.166
- Note que, mesmo com heterocesdasticidade, é possível recuperar $\hat{b} \approx b_0$. Mas, observe também que, se a amostra for pequena, mais provável é que $\hat{b} \neq b_0$. Teste diversas vezes para $N$ menores.
Qualidade do ajuste
- Seção 2.3 de Heiss (2020)
- A soma de quadrados total (SQT), a soma de quadrados explicada (SQE) e a soma de quadrados dos resíduos (SQR) podem ser escritos como:
\begin{align} SQT &= \sum^n_{i=1}{(y_i - \bar{y})^2} = (n-1) . Var(y) \tag{2.10}\\ SQE &= \sum^n_{i=1}{(\hat{y}_i - \bar{y})^2} = (n-1) . Var(\hat{y}) \tag{2.11}\\ SQR &= \sum^n_{i=1}{(\hat{u}_i - 0)^2} = (n-1) . Var(\hat{u}) \tag{2.12} \end{align} em que $Var(x) = \frac{1}{n-1} \sum^n_{i=1}{(x_i - \bar{x})^2}$.
- Wooldridge (2006) define o coeficiente de determinação como: \begin{align} R^2 &= \frac{SQE}{SQT} = 1 - \frac{SQR}{SQT}\\ &= \frac{Var(\hat{y})}{Var(y)} = 1 - \frac{Var(\hat{u})}{Var(y)} \tag{2.13} \end{align} pois $SQT = SQE + SQR$.
# Calculando R^2 de três maneiras:
var(sal_hat) / var(sal)
## [1] 0.01318862
1 - var(u_hat)/var(sal)
## [1] 0.01318862
cor(sal, sal_hat)^2 # correlação ao quadrado da variável dependente com valores ajustados
## [1] 0.01318862
- Para obter o
$R^2$ de forma mais conveniente, pode-se usar a função
summary()sobre o objeto de resultado da regressão. Esta função fornece uma visualização dos resultados mais detalhada, incluindo o $R^2$:
summary(CEOregres)
##
## Call:
## lm(formula = salary ~ roe, data = ceosal1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1160.2 -526.0 -254.0 138.8 13499.9
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 963.19 213.24 4.517 1.05e-05 ***
## roe 18.50 11.12 1.663 0.0978 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1367 on 207 degrees of freedom
## Multiple R-squared: 0.01319, Adjusted R-squared: 0.008421
## F-statistic: 2.767 on 1 and 207 DF, p-value: 0.09777