- A parte de Econometria no R é baseada no livro de Florian Heiss “Using R for Introductory Econometrics” (2ª edição, 2020)
- Aplica no R o conteúdo e os exemplos do livro do Wooldridge de 2019 (versão em inglês)
- É possível ler gratuitamente a versão online em: http://www.urfie.net
- Há também uma versão de Python do livro em: http://www.upfie.net
- A base de dados dos exemplos contidos no livro do Wooldridge podem ser obtidos por meio da instalação e do carregamento do pacote
wooldridge:
# install.packages("wooldridge")
library(wooldridge)
Distribuições
-
Probability Distributions in R (Examples): PDF, CDF & Quantile Function (Statistics Globe)
-
As funções relacionadas a distribuições são dadas por
<prefixo><nome da distribuição> -
Existem 4 prefixos que indicam qual ação será realizada:
d: retorna uma probabilidade a partir de uma função de densidade de probabilidade (fdp)p: retorna uma probabilidade acumulada a partir de uma função de distribuição acumulada (fda)q: retorna uma estatística da distribuição (quantil) dada uma probabilidade acumuladar: gera números aleatórios dada a distribuição
-
Existem diversas distribuições disponíveis no R:
norm: Normalbern: Bernoulli (pacoteRlab)binom: Binomialpois: Poissonchisq: Qui-Quadrado ( $\chi^2$)t: t-Studentf: Funif: Uniformeweibull: Weibullgamma: Gammalogis: Logísticaexp: Exponencial
-
Seguem as principais distribuições e suas respectivas funções:
| Distribuição | Densidade de Probabilidade | Distribuição Acumulada | Quantil |
|---|---|---|---|
| Normal | dnorm(x, mean, sd) |
pnorm(q, mean, sd) |
qnorm(p, mean, sd) |
| Qui-Quadrado | dchisq(x, df) |
pchisq(q, df) |
qchisq(p, df) |
| t-Student | dt(x, df) |
pt(q, df) |
qt(p, df) |
| F | df(x, df1, df2) |
pf(q, df1, df2) |
qf(p, df1, df2) |
| Binomial | dbinom(x, size, prob) |
pbinom(q, size, prob) |
qbinom(p, size, prob) |
em que x e q são estatísticas de cada distribuição (quantis), e p é probabilidade.
Distribuição Normal
- Considere uma normal padrão, $N(\mu=0, \sigma=1)$, e escores padrão $Z=-1,96 \text{ e } 1,96$ (para intervalo de confiança de $\approx 5\%$):

- [
d]: Densidade a partir de uma fdp, dada estatística (escore padrão):
dnorm(1.96, mean=0, sd=1) # probabilidade para escore padrão de 1,96
## [1] 0.05844094
dnorm(-1.96, mean=0, sd=1) # probabilidade para escore padrão de -1,96
## [1] 0.05844094
- [
p]: Probabilidade acumulada a partir de uma fda, dada estatística (escore padrão):
pnorm(1.96, mean=0, sd=1) # probabilidade acumulada para escore padrão de 1,96
## [1] 0.9750021
pnorm(-1.96, mean=0, sd=1) # probabilidade acumulada para escore padrão de -1,96
## [1] 0.0249979
Logo, a probabilidade de que uma variável aleatória com distribuição normal padrão esteja com valor entre -1,96 e 1,96 é de 95%
pnorm(1.96, mean=0, sd=1) - pnorm(-1.96, mean=0, sd=1)
## [1] 0.9500042
- [
q]: Estatística (escore padrão) a partir de um quantil:
qnorm(0.975, mean=0, sd=1) # quantil dada o quantil de 97,5%
## [1] 1.959964
qnorm(0.025, mean=0, sd=1) # quantil dada o quantil de 2,5%
## [1] -1.959964
Podemos criar gráficos usando a função curve( function(x), from, to ), na qual inserimos uma função com um x arbitrário e seus limites mínimo e máximo (from e to):
# pdf de normal padrão com estatística (escore padrão) no intervalo -3 e 3
curve(dnorm(x, mean=0, sd=1), from=-3, to=3)
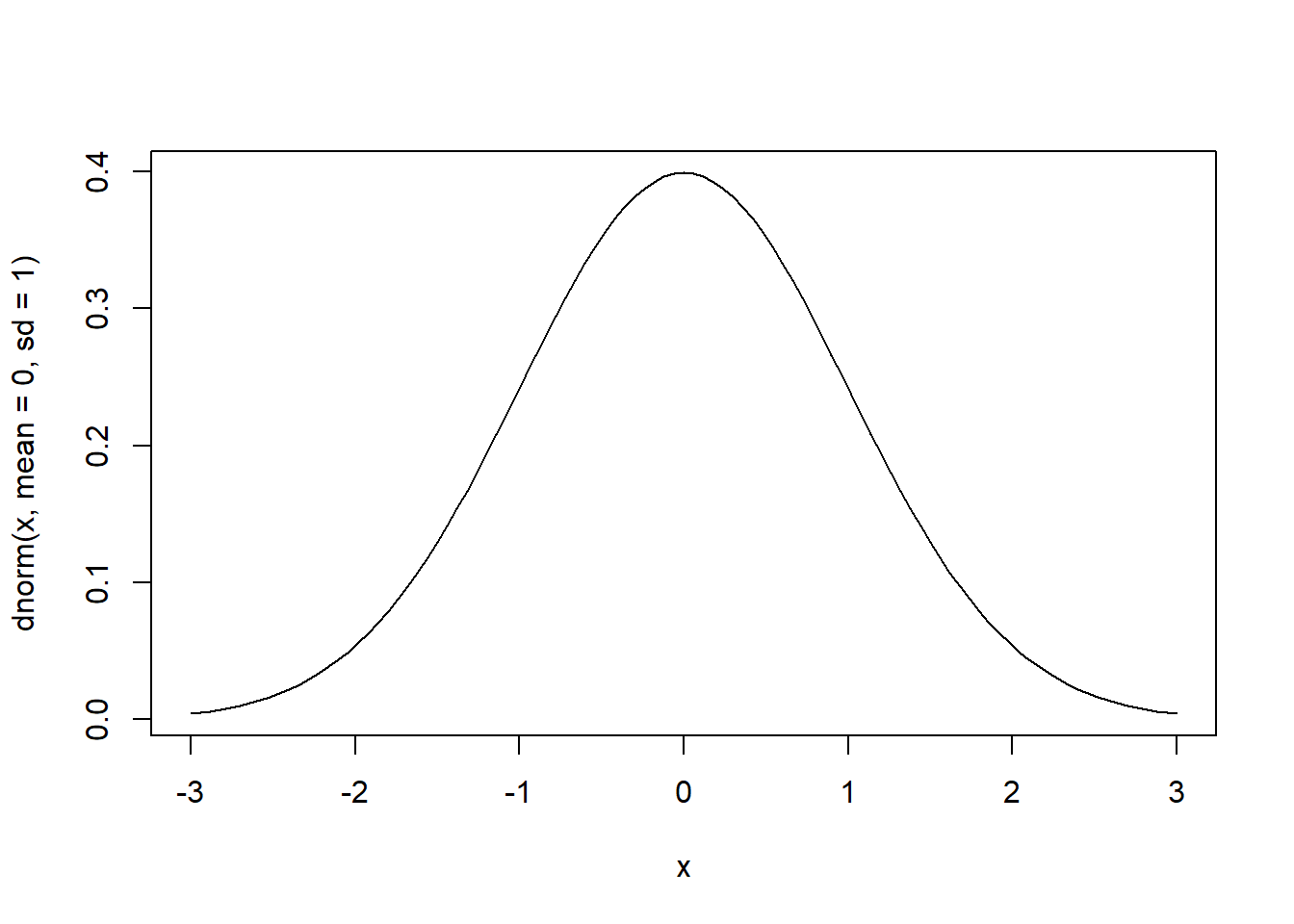
# cdf de normal padrão com estatística (escore padrão) no intervalo -3 e 3
curve(pnorm(x, mean=0, sd=1), from=-3, to=3)
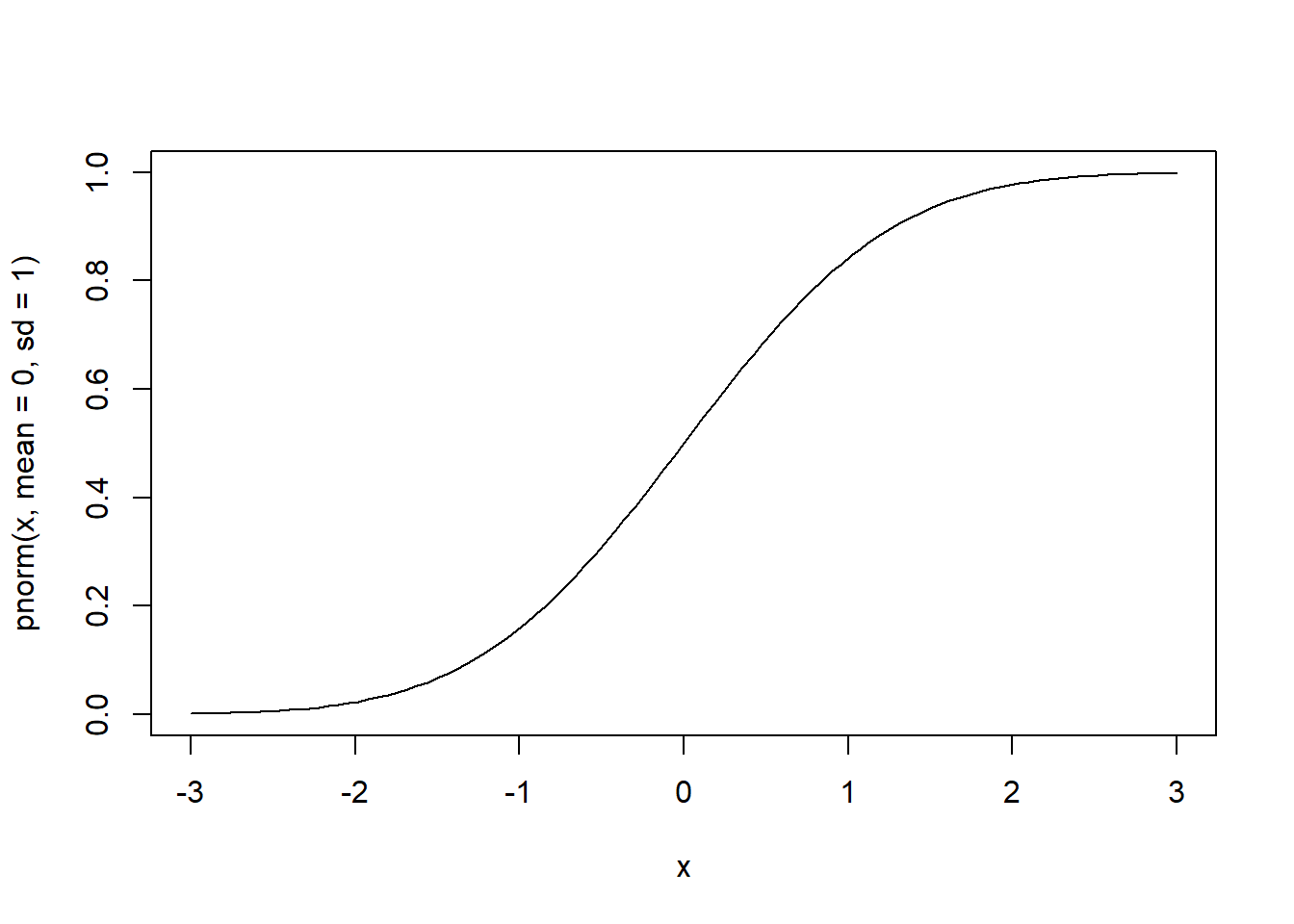
# quantil de normal padrão com probabilidade acumulada no intervalo 0 e 1
curve(qnorm(x, mean=0, sd=1), from=0, to=1)
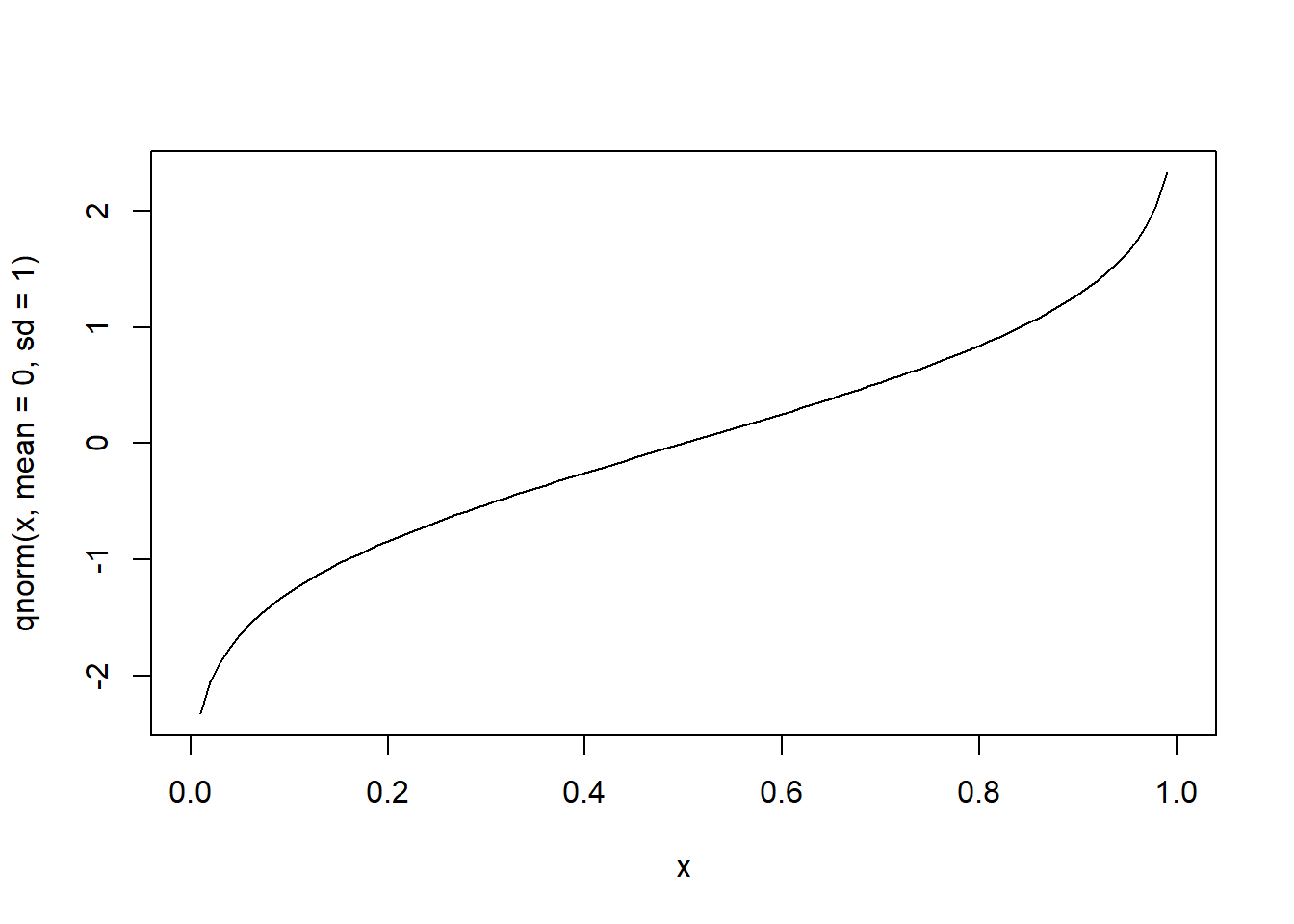
Distribuição t-Student
- Criaremos gráficos com diversos graus de liberdade
- Quanto maior os graus de liberdade, mais se aproxima de uma normal padrão
curve(dnorm(x, mean=0, sd=1), from=-3, to=3, pch=".") # fdp normal padrão
for (n in c(10, 5, 3, 2)) {
curve(dt(x, df=n), from=-3, to=3, col=n, add=T) # fdp t-student
}
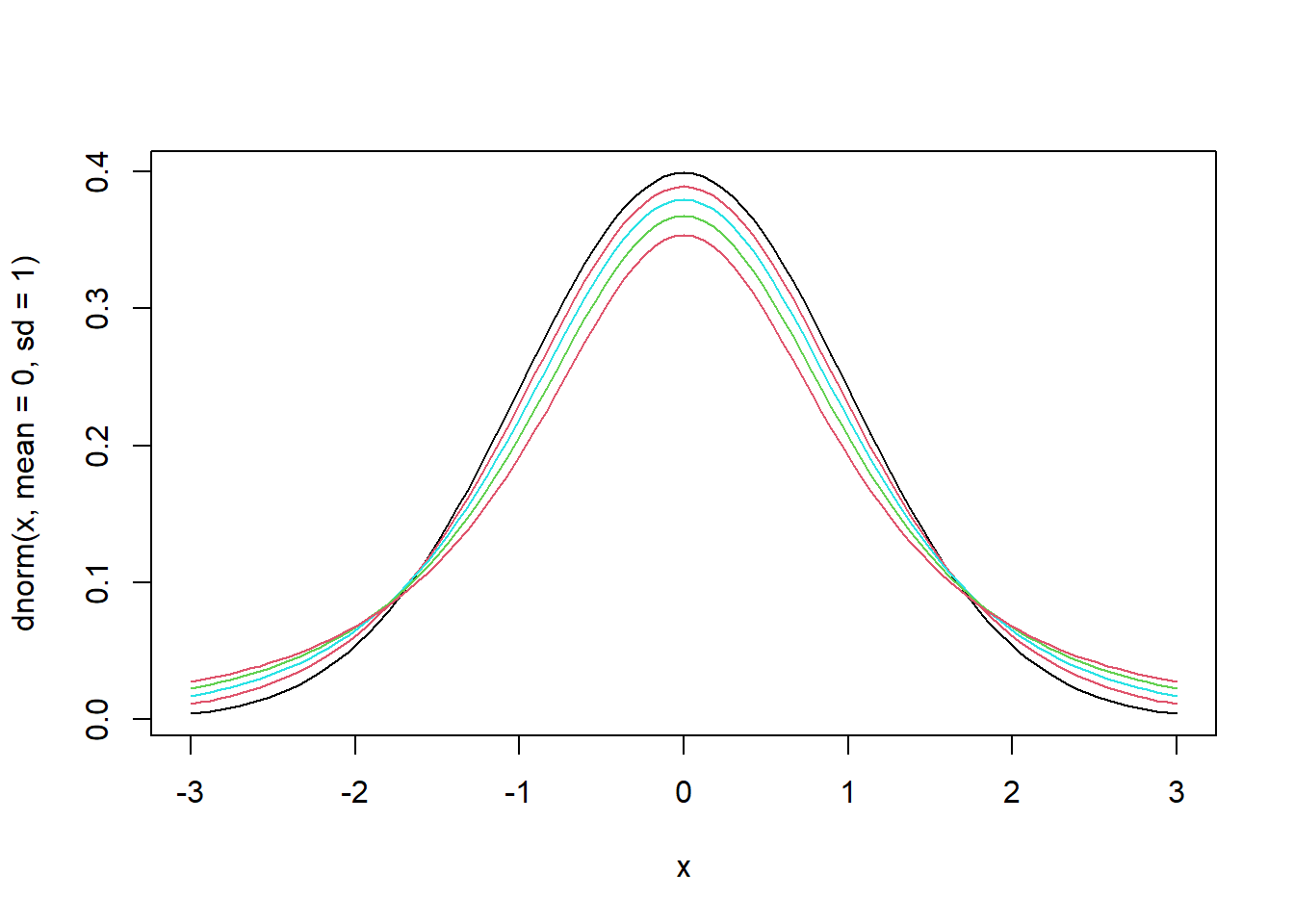
Simulação
Amostragem aleatória
- Simulation - Random sampling (John Hopkins/Coursera)
- Para fazer uma amostragem a partir de um dado vetor, usamos a função
sample()
sample(x, size, replace = FALSE, prob = NULL)
x: either a vector of one or more elements from which to choose, or a positive integer. See ‘Details.’
n: a positive number, the number of items to choose from.
size: a non-negative integer giving the number of items to choose.
replace: should sampling be with replacement?
prob: a vector of probability weights for obtaining the elements of the vector being sampled.
sample(letters, 5) # Amostragem de 5 letras
## [1] "w" "n" "m" "j" "h"
sample(1:10, 4) # Amostragem de 4 números de 1 a 10
## [1] 5 10 8 6
sample(1:10) # Permutação (amostra mesma qtd de elementos do vetor)
## [1] 2 10 6 1 5 9 7 3 4 8
sample(1:10, replace = TRUE) # Amostragem com reposição
## [1] 2 9 9 4 5 1 10 1 4 5
- Note que, por padrão, a função
sample()faz a amostragem sem reposição.
Visualizando a Lei dos Grandes Números (LGN)
- Podemos usar a amostragem para simular jogadas de dado não viesado.
- Vamos jogar uma vez o dado:
sample(1:6, 1) # amostra um número dentro do vetor 1:6
## [1] 4
- Vamos jogar 500 vezes o dado (usando função
replicate()) e verificar sua distribuição:
amostra = replicate(500, expr=sample(1:6, 1))
table(amostra) # tabela com contagem das jogadas
## amostra
## 1 2 3 4 5 6
## 74 85 83 99 78 81
# Gráfico
plot(table(amostra), type="h")
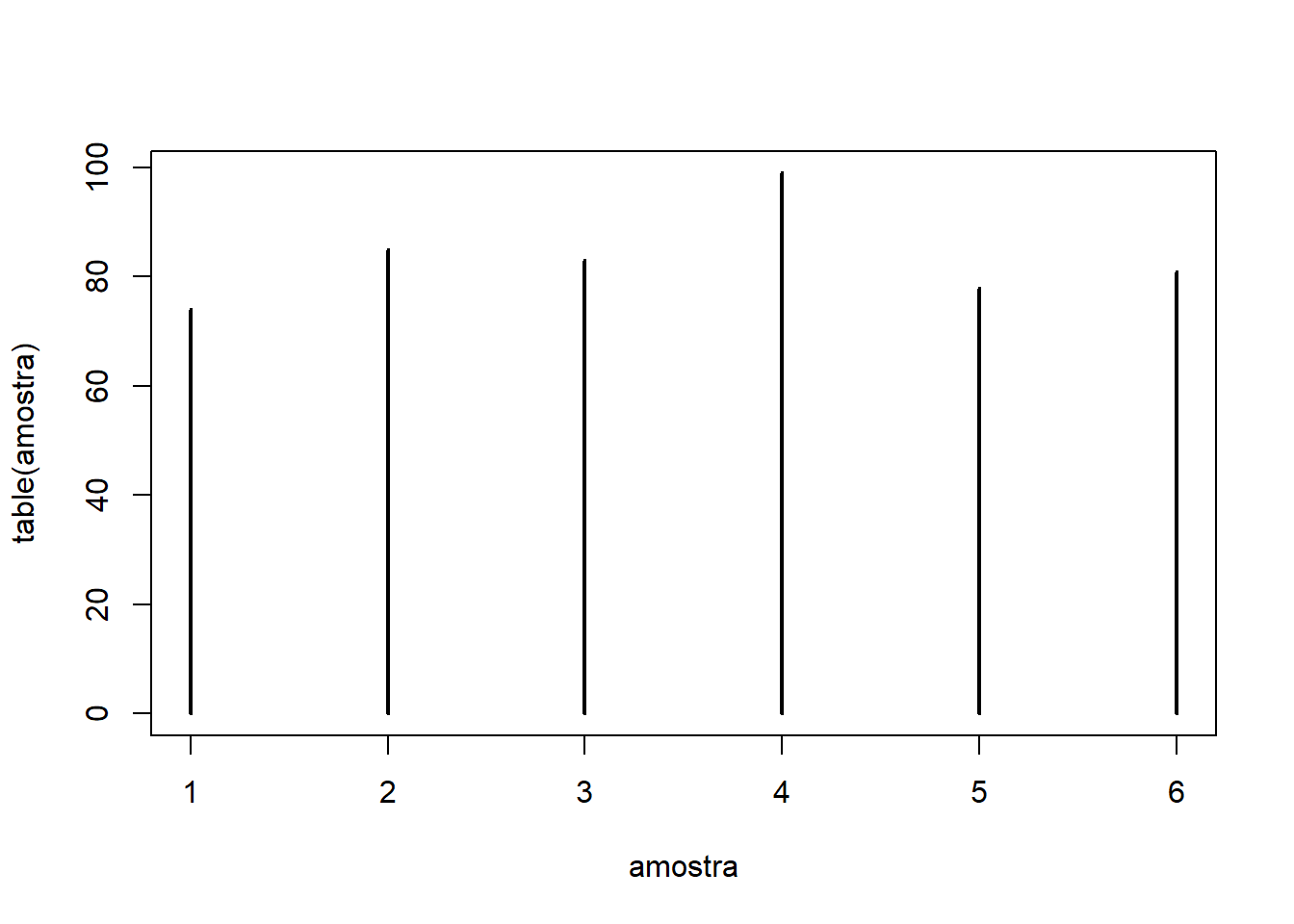 - Note que não podemos usar a função `rep()` com simulação, pois ele sortearia um número e replicaria esse mesmo número 500 vezes.
- Agora, vamos jogar 2 vezes o dado e fazer a média entre eles
- Note que não podemos usar a função `rep()` com simulação, pois ele sortearia um número e replicaria esse mesmo número 500 vezes.
- Agora, vamos jogar 2 vezes o dado e fazer a média entre eles
mean(sample(1:6, 2))
## [1] 3.5
- Fazendo isso 500 vezes, temos:
amostra = replicate(500, mean(sample(1:6, 2, replace=T)))
table(amostra) # tabela com contagem das médias de 2 jogadas
## amostra
## 1 1.5 2 2.5 3 3.5 4 4.5 5 5.5 6
## 10 27 47 61 71 83 61 44 42 33 21
# Gráfico
plot(table(amostra), type="h")
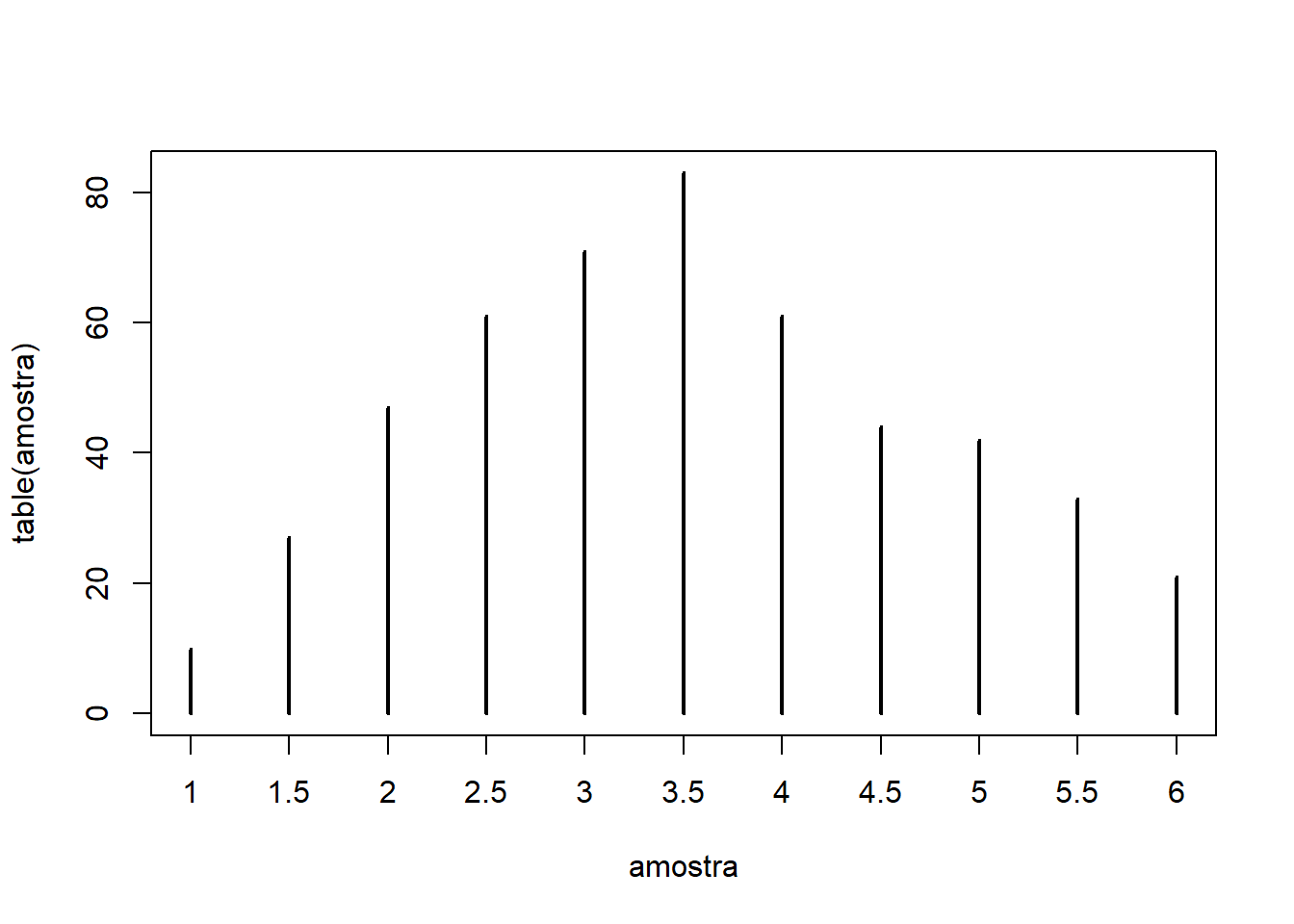
- Note que, ao repetir 500 vezes, o cálcilo da média de 2 jogadas de dado, começou a dar mais peso para médias próximas à média populacional (3,5), mas ainda tem densidade nos valores mais extremos (1 e 6)
- Foi necessário usar o argumento
replace=TRUEpara ter “reposição” dos números do dado - Calculando 500 vezes a média de $N=100$ jogadas de dado, temos:
N = 100
amostra = replicate(500, mean(sample(1:6, N, replace=T)))
# Gráfico
plot(table(amostra), type="h", xlim=c(1,6))
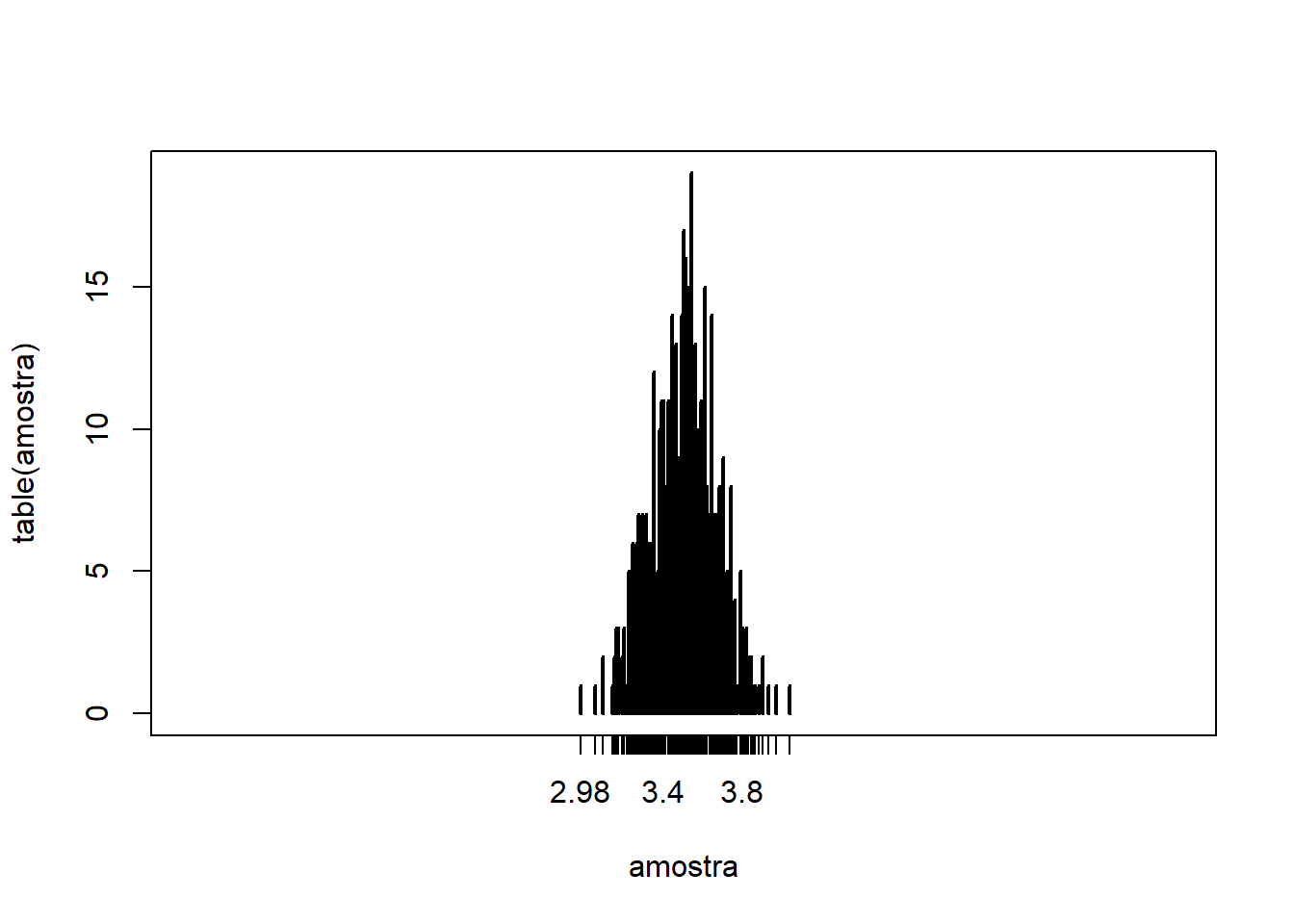
- Note que, quanto maior $N$, a concentração das médias das amostragens se concentraram ainda mais próximo da média populacional (3,5). Além disso, a densidade de médias mais distantes ficaram praticamente nulas.
Geração de números aleatórios
- Para gerar números aleatórios, usaremos o prefixo
rjunto de uma distribuição.
rnorm(5) # gerando 5 números aleatórios
## [1] -0.8829037 -0.5396110 0.3302621 0.4478966 -0.5543385
- Para reproduzir resultados que usem números aleatórios, podemos definir “sementes” usando a função
set.seed()e informando um número inteiro. Isso também é válido para a funçãosample().
# definindo seed
set.seed(2022)
rnorm(5)
## [1] 0.9001420 -1.1733458 -0.8974854 -1.4445014 -0.3310136
# sem definir seed
rnorm(5)
## [1] -2.9006290 -1.0592557 0.2779547 0.7494859 0.2415825
# definindo seed
set.seed(2022)
rnorm(5)
## [1] 0.9001420 -1.1733458 -0.8974854 -1.4445014 -0.3310136
Intervalos de Confiança
- Subseção 1.8.1 de Heiss (2020)
- No Apêndice C.5 de Wooldridge (2006, em português), são construídos intervalos de confiança de 95%.
- Para uma população normalmente distribuída com média
$\mu$ e variância
$\sigma^2$, o intervalo de confiança com significância de
\(\alpha\)é dado por:
$$ \text{IC}\alpha = \left[\bar{y} - C{\alpha/2}.se(\bar{y}),\quad \bar{y} + C_{\alpha/2}.se(\bar{y})\right] \tag{1.2} $$ em que:
- $\bar{y}$: média amostral
- $se(\bar{y}) = \frac{s}{\sqrt{n}}$: erro padrão de $\bar{y}$
- $s$: desvio padrão de $\bar{y}$
- $n$: tamanho da amostra
-
$C_{\alpha/2}$: é o valor crítico do quantil de
$(1-\alpha/2)$ da distribuição
$t_{n-1}$.
- Por exemplo, para $\alpha = 5\%$, usa-se o quantil 97,5% ( $= 1 - 5\%/2$).
- Quando o número de graus de liberdade é grande, a distribuição t se aproxima ao de uma normal padrão. Logo, para um intervalo de confiança de 95%, o valor crítico é $C_{2,5\%} \approx 1,96$
Exemplo C.2: Efeito de subsídios de treinamento corporativo sobre a produtividade do trabalhador (Wooldridge, 2006)
- Holzer, Block, Cheatham e Knott (1993) estudaram os efeitos de subsídios de treinamentos corporativos sobre a produtividade dos trabalhadores
- Para isto, avaliou-se a “taxa de refugo”, isto é, a quantidade de itens descartados a cada 100 itens produzidos.
- Entre 1987 e 1988, houve treinamento corporativo em 20 empresas e queremos saber se ele teve efeito sobre a taxa de refugo, ou seja, a diferença entre as médias dos anos foi estatisticamente significante (diferente de 0).
- Comecemos criando vetores de taxa de refugos das 20 empresas para os anos de 1987 (SR87) e de 1988 (SR88):
SR87 = c(10, 1, 6, .45, 1.25, 1.3, 1.06, 3, 8.18, 1.67, .98,
1, .45, 5.03, 8, 9, 18, .28, 7, 3.97)
SR88 = c(3, 1, 5, .5, 1.54, 1.5, .8, 2, .67, 1.17, .51, .5,
.61, 6.7, 4, 7, 19, .2, 5, 3.83)
- Criando o vetor das variações das taxas de refugo e extraindo estatísticas:
Change = SR88 - SR87 # vetor de variações
n = length(Change) # quantidade de empresas/tamanho do vetor Variacao
avgChange = mean(Change) # média do vetor Variacao
sdChange = sd(Change) # desvio padrão do vetor Variacao
- Calculando o erro padrão e o valor crítico para intervalo de confiança de 95%:
se = sdChange / sqrt(n) # erro padrão
CV = qt(.975, n-1) # valor crítico para intervalo de confiança de 95%
- Finalmente, calcula-se o intervalo de confiança usando (1.2)
c(avgChange - CV*se, avgChange + CV*se) # limites inferior e superior do intervalo
## [1] -2.27803369 -0.03096631
# também poderíamos escrever o intervalo mais sucintamente:
avgChange + CV * c(-se, se)
## [1] -2.27803369 -0.03096631
- Note que o valor 0 está fora do intervalo de confiança de 95% e, portanto, conclui-se que houve alteração na taxa de refugo (houve efeito negativo estatisticamente significante).
Teste t e p-valores
-
Apêndice C.6 de Wooldridge (2006, em português)
-
A estatística t para testar uma hipótese sobre uma variável aleatória $y$ normalmente distribuída com média $\bar{y}$ é dado pela equação C.35 (Wooldridge, 2006). Dada a hipótese nula $H_0: \bar{y} = \mu_0$, $$ t = \frac{\bar{y} - \mu_0}{se(\bar{y})}. \tag{1.3} $$
-
Para rejeitarmos a hipótese nula, o módulo da estatística t precisa ser maior do que o valor crítico, dado um nível de significância $\alpha$.
-
Por exemplo, ao nível de significância $\alpha = 5\%$ e com uma grande amostra (e, portanto, a distribuição t se aproxima a de uma normal padrão), rejeitamos a hipótese nula se $$ |t| \ge 1,96 \approx \text{valor crítico ao nível de significância de 5%} $$
-
A vantagem de utilizar o p-valor é a sua conveniência, pois pode-se compará-lo diretamente com o nível de significância.
-
Para testes t bicaudais, a fórmula do p-valor é dado por (Wooldridge, 2006, equação C.42): $$ p = 2.Pr(T_{n-1} > |t|) = 2.[1 - F_{t_{n-1}}(|t|)] $$ em que $F_{t_{n-1}}(\cdot)$ é a fda da distribuição $t_{n-1}$.

- Rejeitamos a hipótese nula se o p-valor for menor do que o nível de significância $\alpha$.
Exemplo C.6: Efeito de subsídios de treinamento corporativo sobre a produtividade do trabalhador (Wooldridge, 2006)
- Continuação do exemplo C.2
- Considerando teste bicaudal (diferente dos livros), podemos calcular a estatística t
# Estatística t para H0: mu = 0
t = (avgChange - 0) / se
print(paste0("estatística t = ", abs(t), " > ", CV, " = valor crítico"))
## [1] "estatística t = 2.15071100397349 > 2.09302405440831 = valor crítico"
- Como estatística t é maior do que o valor crítico, rejeitamos $H_0$ a nível de significância de 5%.
- De forma equivalente, podemos calcular o p-valor:
p = 2 * (1 - pt(abs(t), n-1))
print(paste0("p-valor = ", p, " < 0.05 = nível de significância"))
## [1] "p-valor = 0.0445812529367844 < 0.05 = nível de significância"
- Como o p-valor é maior do que $\alpha = 5\%$, rejeitamos $H_0$.
Cálculos via t.test()
t.test(x, y = NULL,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, var.equal = FALSE,
conf.level = 0.95, ...)
x: (non-empty) numeric vector of data values.
alternative: a character string specifying the alternative hypothesis, must be one of "two.sided" (default), "greater" or "less". You can specify just the initial letter.
mu: a number indicating the true value of the mean (or difference in means if you are performing a two sample test).
conf.level: confidence level of the interval.
- Note que incluiremos um vetor de valor no argmento
xe, por padrão, a função considera um teste bicaudal, testando a $H_0$ se média verdadeira é igual a zero e com intervalo de confiança de 95%. - Retornando aos exemplos C.2 e C.6 (“Efeito de subsídios de treinamento corporativo sobre a produtividade”), temos:
testresults = t.test(Change)
testresults
##
## One Sample t-test
##
## data: Change
## t = -2.1507, df = 19, p-value = 0.04458
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## -2.27803369 -0.03096631
## sample estimates:
## mean of x
## -1.1545
- Dentro do objeto de resultado do teste, temos as seguintes informações:
names(testresults)
## [1] "statistic" "parameter" "p.value" "conf.int" "estimate"
## [6] "null.value" "stderr" "alternative" "method" "data.name"
- Podemos, por exemplo, acessar o p-valor usando:
testresults$p.value
## [1] 0.04458125